Overview
Graph Neural Networks (GNNs) can deliver state-of-the-art model performance when used correctly. However, like many other deep learning techniques, there is no “one size fits all” approach to designing your GNNs. In order to deliver the best performance, GNNs architecture must to be customized to your dataset and problem. For example, on a recent customer dataset, we saw that a well-tuned GNN had 70% better performance than a poorly-tuned one. Picking the best GNNs architecture for your problem is a difficult task. The landscape of GNN architectures is quite diverse, and there are many choices to choose from. For example, if you are trying to generate product recommendations for customers, you will likely want to use a combination of identity aware graph neural networks and neural graph collaborative filtering to get the best model quality. However, for other types predictive queries such as LTV, customer churn, and demand forecasting, you will need to use very different architectures. Unless you follow latest research in deep learning, it can be hard to know which architecture is best for your specific problem. In order to help you find the best GNN architecture for your dataset, Kumo provides two powerful tools:- AutoML: By default, Kumo’s AutoML algorithm will analyze your dataset and predictive query, to construct a training plan and GNN architecture search space that is tailored to your dataset. This plan will search a variety of different architectures that are known to work well for your problem space, incorporating the most recent techniques from recent research in the GNN community.
- Model Planner: In situations where you need more control, Kumo exposes a model planner that give you fine grained control over the shape and structure of the GNN for your dataset. Additionally, the model planner will give you control over column encoding, training table generation, and sampling. Using this model planner, experienced data scientists should be able to squeeze out a bit of extra performance when it really matters.
Kumo and AutoML
Whether you’re a startup looking to make sense of your data or a large enterprise seeking to optimize your operations, Kumo’s implementation of AutoML helps accelerate your model deployment efforts, allowing you to focus on the insights and value generated from your data, rather than the intricacies of model development.How It Works
Whenever you write a new predictive query, the Kumo AutoML system will generate a modeling plan that covers three areas: column encoding, training table generation, and GNN architecture search.Column Encoding
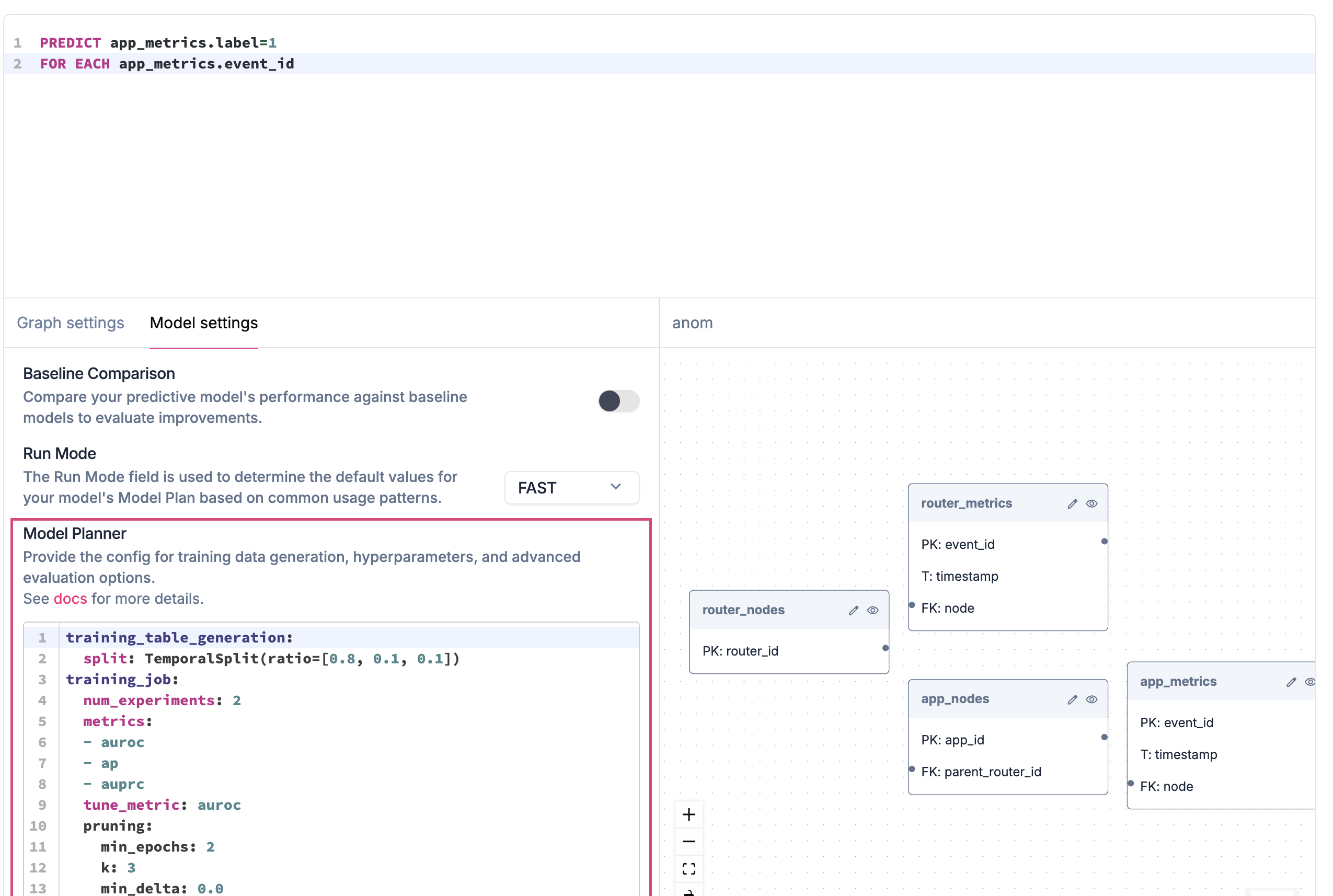
Though GNNs largely eliminate the need for manual feature engineering, column encoding is still required to transform your raw tabular data into the actual bits and bytes that get feed into the neural network.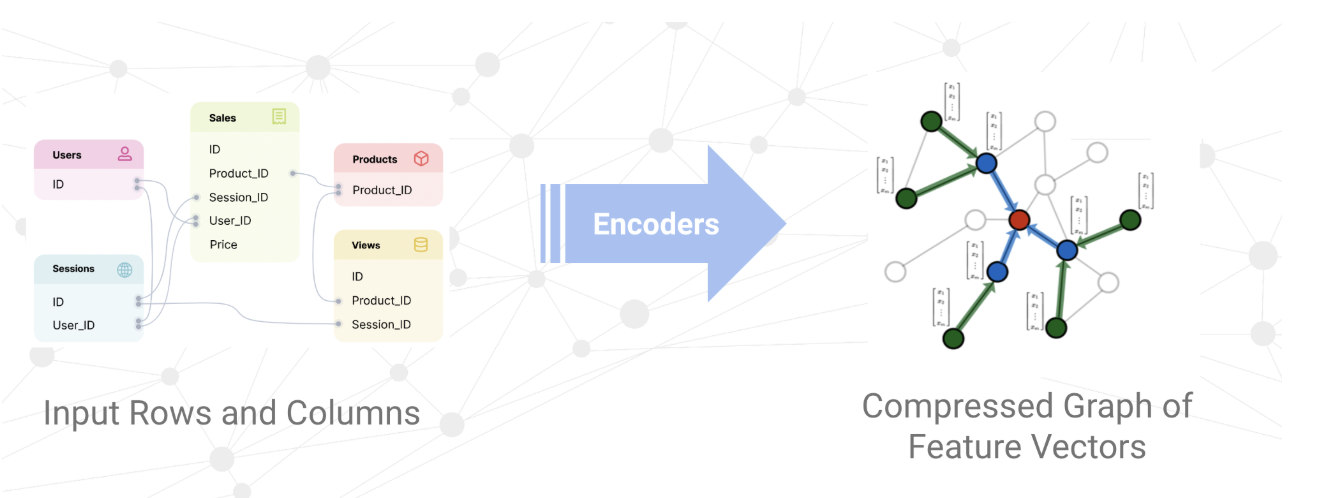
Hash encoder if the column represents a high-cardinality identifier like product_code, Datetime encoder if it represents a Unix timestamp, Numerical encoder if it represents a quantity such as num_visits, or Index encoder if it represent a boolean True/False value. The Kumo AutoML algorithm fully automates this process for you—for all possible input data types—including text, numbers, categories, strings, and even arrays.
Training Table Generation
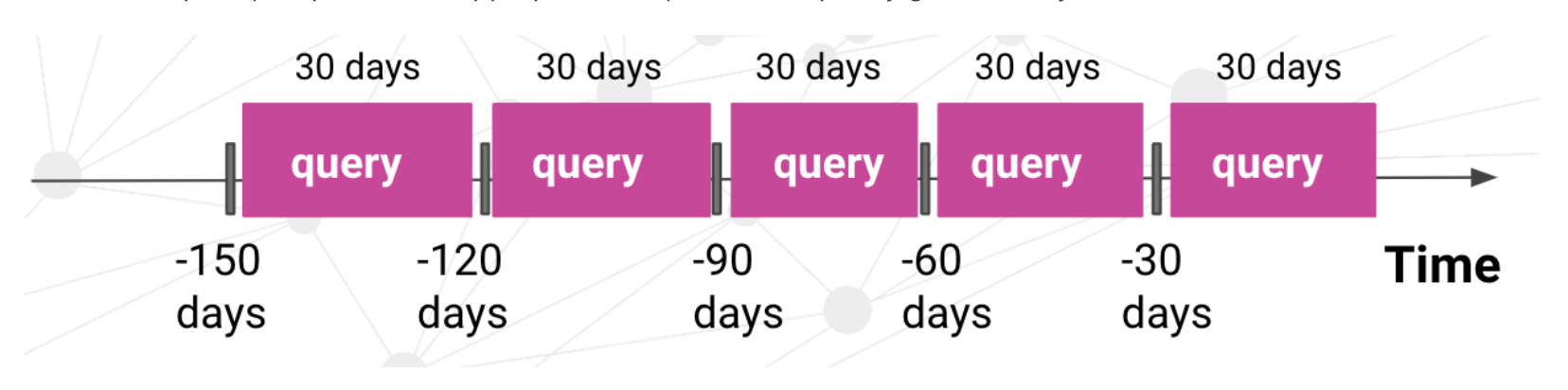
When training a machine learning model, the creation of a training table with multiple data splits is generally required, such as train, validation, and holdout. Crucially, these these splits should be non-overlapping and properly ordered when dealing with temporal queries that make predictions about the future, or else you risk data leakage and invalidating your results. Splits should also be well-balanced in terms of size. Training table generation becomes even more complicated when predicting complex events, such as aggregations over time. For example, suppose that you are trying to generate a training table for the following predictive task that predicts events over a 30 day window.
GNN Architecture and Hyper-parameter Search
Graph neural networks don’t refer to a single model architecture, but rather an entire family of model architectures, each with their own pros and cons. Kumo fuses many state-of-the-art GNN architectures, such as GraphSAGE, GIN, ID-GNN, GCN, PNA, and GAT, into a flexible, in-house module that gets the best of all these existing GNN models. Kumo AutoML automatically decides the best model hyper-parameters and training strategies depending on your specific predictive query and dataset. The hyper-parameters affect things such as the neighborhood sampling method, layer connectivity, embedding size, and aggregation methods.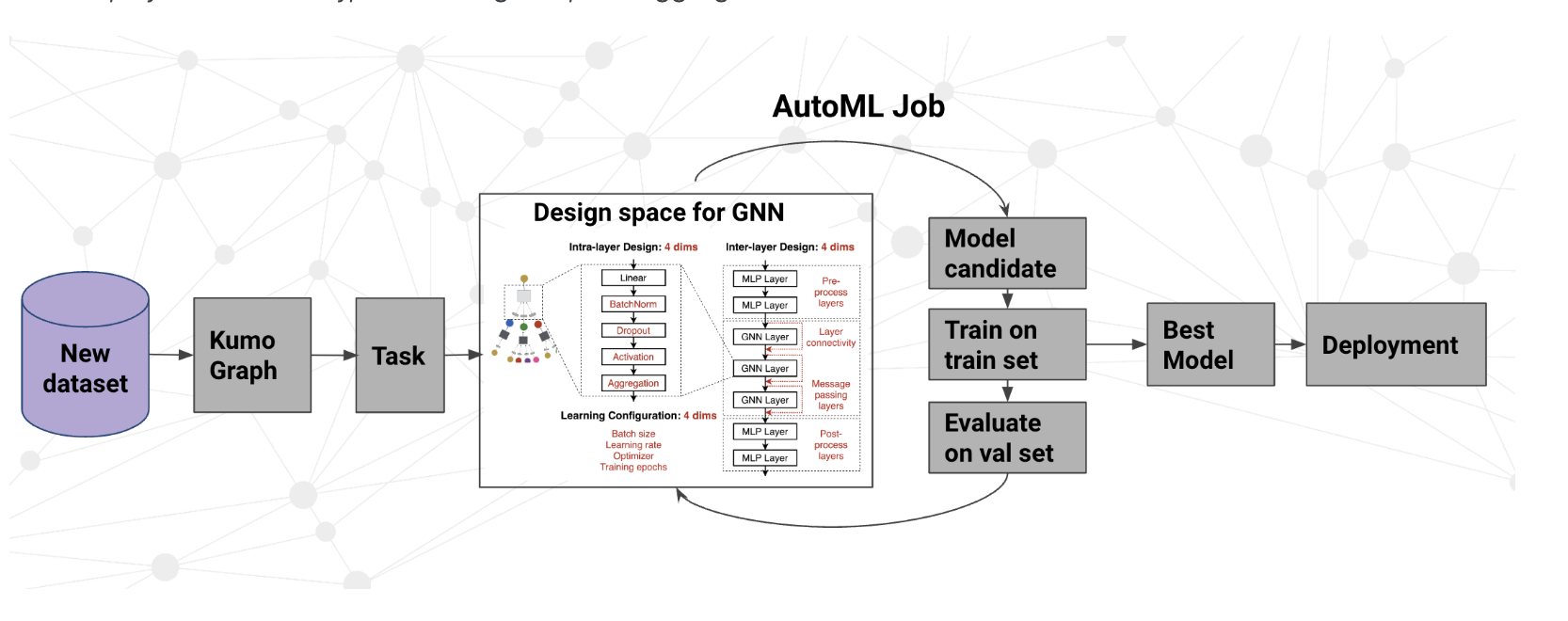
Fine Grained Control using Kumo’s Model Planner
If you need fine-grained control over the encoders, training strategy, or AutoML search space, you can use Kumo’s model planner. Though customizing the model planner settings is usually not necessary, you might want to do this in a few scenarios:- Control the Data Split Strategy - The most common reason to use the model planner is to control the data split strategy. For example, using the
TimeRangeSplitmodule to specify the exact holdout dataset is common practice for comparing model performance against an existing model trained outside of Kumo. You can also enforce additional constraints required by your organization (e.g., ensuring a sufficiently large gap between the training dataset and the holdout dataset). - Make your Jobs Run Faster - If you already know what kind of model architecture you want (e.g., based on your experience writing similar predictive queries on your dataset), you can use the model planner to skip the full AutoML architecture search, and focus on optimizing on a very narrow portion of the search space. For example, if you only run one experiment instead of eight, you can potentially make your job eight times faster and increase your productivity as a data scientist.
- Maximize Performance - Additionally, if an additional 1-5% of improved performance is critical, you can use the model planner to eke out more performance—however, this may occur at the cost of increased job runtime or other lost functionality. For example, the default model plan usually caps the number of channels to 256, since the performance benefit usually does not outweigh the cost beyond that point; however, you are free to push the limit. Or, if you know what you are doing, you can use something like the
refitoption, which trains over the entire dataset, at the cost of losing evaluation metrics on the holdout dataset. - Control the Data Encoding - In certain situations, you may want to control exactly how your data is encoded before it gets passed into the GNN. For example, for a particular numerical column, you may want missing values to be treated the same as
0, or enable a more expensive NLP encoding method for a particular text column that you feel is particularly important. - Change the Optimization Method - Out of the box, Kumo will optimize metrics like AUROC, Loss, MAE. However, you can use the
tune_metricoption to change the behavior. This is particularly useful in the case of recommendation problems, where you can use themoduleoption to optimize the recommender for different goals (such as diversity vs recall). - Exporting Embeddings - If you intend to export embeddings for use as features in a downstream model or as part of KNN lookup in a recommender system, you can modify several options in the model planner to ensure that the embeddingshave the desired properties to meet your needs. For example, do you need the embeddings to be stable across model retraining? Do you plan to use cosine similarity to compare embeddings? Or, if you do not care about embeddings at all, you can enable advanced types of GNN architectures (e.g, ID-GNN) to improve your model accuracy at the cost of not supporting embeddings.