Overview
Evaluating your model training ensures that its performance meets expectations and drives meaningful impact. Kumo provides built-in evaluation tools to assess model accuracy using unseen data. Kumo evaluates each model against the most recent time period in historical data (the holdout set) without incorporating that data into the training process. The Evaluation tab in the predictive query detail page provides a comprehensive performance analysis. By default, Kumo uses the most recent time window for evaluation, aligned with the predictive query’s prediction window. For instance, a 30-day prediction window will use the last 30 days of historical data for evaluation, while the remaining data is used for training. These settings can be adjusted in the model plan when creating or editing a predictive query.Validation Data Split and Evaluation Process
Kumo partitions historical training data into three key splits:- Holdout Data Split: The most recent timeframe, used exclusively for final model evaluation, ensuring generalization to unseen data.
- Validation Data Split: The second-most recent timeframe, used during experimentation to identify the best-performing model.
- Training Data Split: All earlier timeframes, used to train multiple candidate models during the search process.
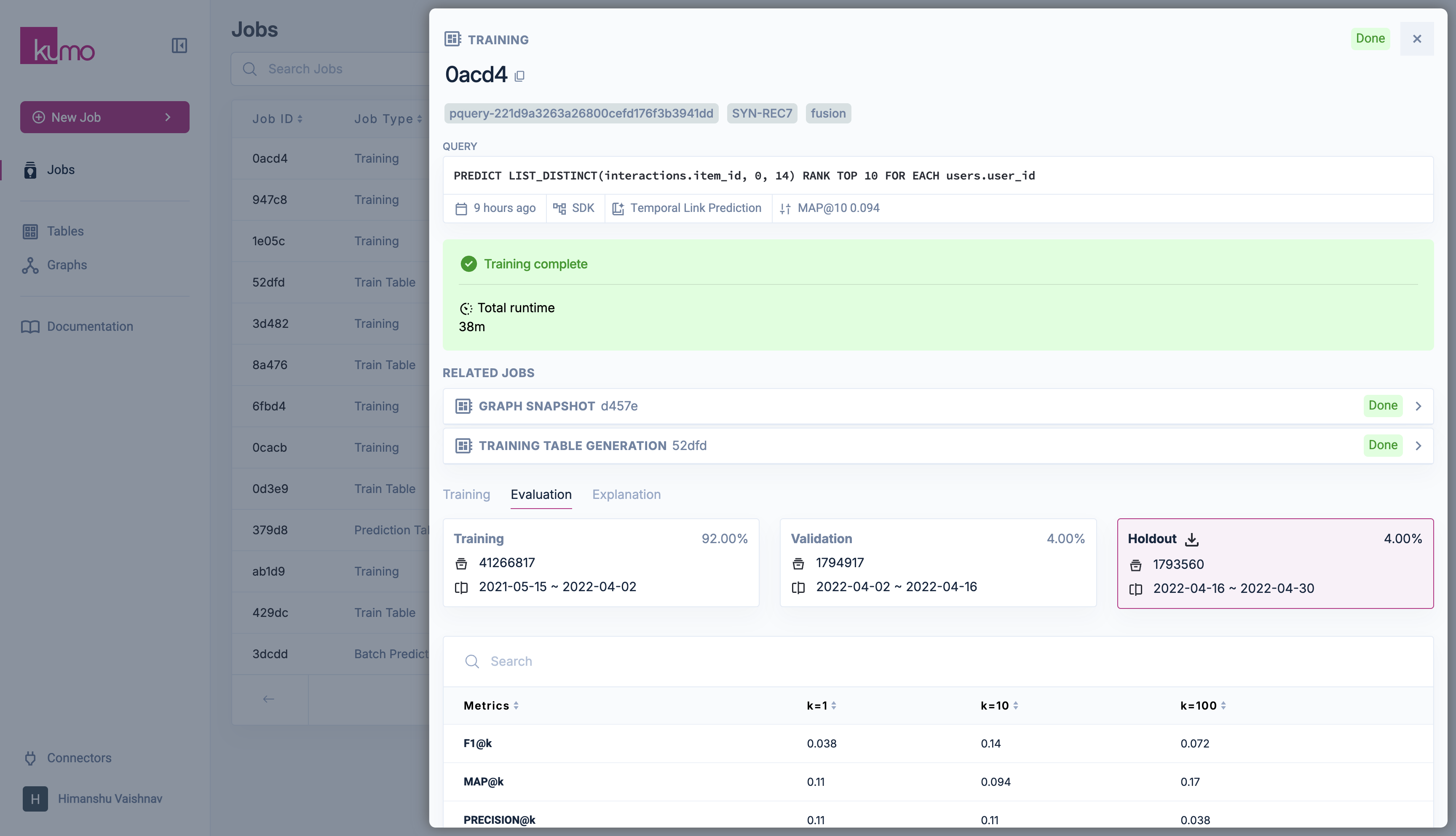
Evaluation Metrics
Kumo selects evaluation metrics based on the predictive query’s target type.Binary Classification
For queries predicting one of two values (e.g., true/false):- Accuracy
- Area Under The Receiver Operating Characteristic Curve (AUROC)
- Area Under The Precision-Recall Curve (AUPRC)
- Confusion Matrix
-
Gain Chart
For more details see classification metrics.
Multiclass Classification
For queries predicting three or more categorical values:-
Accuracy
For more details see classification metrics.
Multilabel Classification
For queries predicting one or more categorical values:- AUPRC (macro/micro/per-label)
- AUROC (macro/micro/per-label)
- Average Precision (AP)
LIST_DISTINCT is used over a non-foreign-key categorical column, the task is considered multilabel classification.
For more details see classification metrics.
Link Prediction
For queries returning a list of associated values (e.g.,LIST_DISTINCT over a foreign key column), Kumo provides retrieval metrics for K = 1, 10, 100:
- F1@K
- MAP@K
- Precision@K
-
Recall@K
For more details see Link Prediction Metrics.
Regression
For queries predicting numeric values (e.g.,SUM, MAX, etc.):
- Mean Absolute Error (MAE)
- Mean Squared Error (MSE)
- Root Mean Squared Error (RMSE)
- Mean Absolute Percentage Error (MAPE)
- Symmetric Mean Absolute Percentage Error (SMAPE)
-
Distribution of Predictions Histogram
For more details see Regression Metrics.