Prerequisites
The following prerequisites are required in order to run Kumo as a Databricks native application:- A dedicated service principal in your Databricks workspace to be used by Kumo
- A dedicated, all-purpose compute cluster with “Shared” access mode (version 14.3 LTS), with “Can Manage” permissions assigned to the Kumo service principal
- The above cluster needs to be appropriately sized for the amount of anticipated data processed by Kumo. See suggested cluster sizing below:
- Set auto-scaling to a max of 8 AWS r6id-2xlarge equivalent worker nodes for data size under 100GB
- Set auto-scaling to a max of 30 AWS r6id-2xlarge equivalent worker nodes for data size above 100GB under 300GB
- Set auto-scaling to a max of 100 AWS r6id-2xlarge equivalent worker nodes for data size above 300GB
- A dedicated small size Serverless SQL warehouse, with “Can manage” permissions assigned to the Kumo service principal
- Unity Catalog table access assigned to the Kumo service principal
- A dedicated Unity Catalog Volume for which the Kumo service principal can read and write. All Kumo generated data will be stored in this volume.
- Your Databricks workspace host URL
- The cluster ID for the dedicated, all-purpose compute cluster
- The warehouse ID for the dedicated, serverless SQL warehouse
- The name of the catalog and schema containing the tables to be accessed by Kumo
- The UC Volume path for the dedicated Unity Catalog Volume
- The Kumo service principal client ID and secret (client secret should be an OAuth token and not a personal access token)
Required Catalog Permissions
The following table illustrates the list of permissions you should grant to the Kumo service principal:
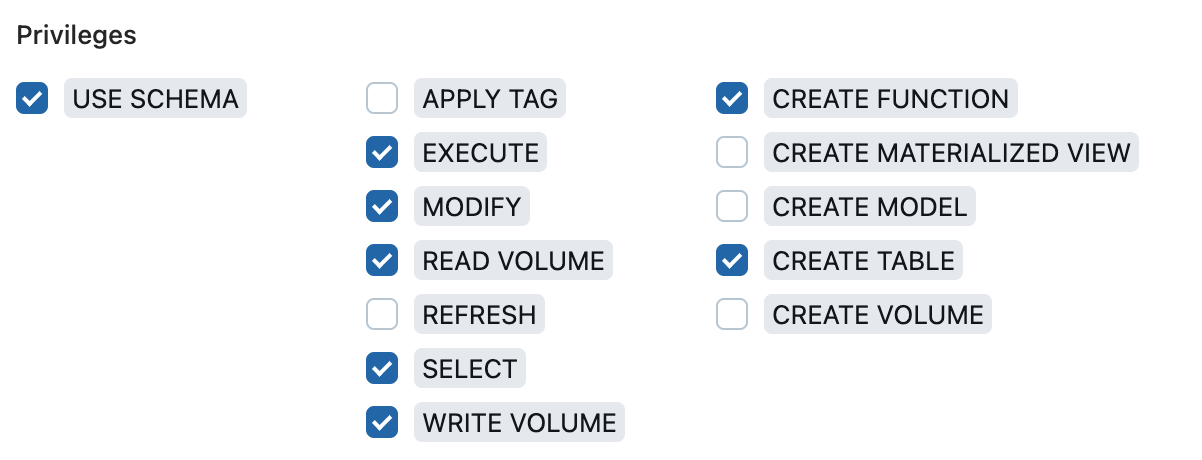 Specifically:
Specifically:
- USE_CATALOG, USE_SCHEMA, EXECUTE, SELECT, CREATE_FUNCTION are needed on the catalog-schema containing tables to be read by Kumo
- USE_CATALOG, USE_SCHEMA, EXECUTE, MODIFY, SELECT, CREATE_FUNCTION, CREATE_TABLE are needed on the catalog-schema in which Kumo writes the batch prediction tables
- USE_CATALOG, USE_SCHEMA, READ_VOLUME, WRITE_VOLUME are needed on the catalog-schema in which Kumo writes intermediate data into your UC Volume
Additional Steps
After creating the above Databricks resources, the following additional steps are needed to set up your Kumo native app for Databricks:JAR File Installation
The Kumo Databricks native app requires the following JAR files:- feature_proto_scala.jar
- lenses_sjs1_2.12-0.11.11.jar
- protobuf-java-3.19.4.jar
- scalapb-runtime_2.12-0.11.11.jar
- sst_source_0.0.1.jar
Step 1: Download the JAR Files The bucket is public and does not require AWS credentials. You can download all required JARs with:
Download all files (public bucket, no AWS credentials required)
for u ins3://kumo-databricks-public/databricks-jars/feature_proto_scala.jar
s3://kumo-databricks-public/databricks-jars/lenses_sjs1_2.12-0.11.11.jar
s3://kumo-databricks-public/databricks-jars/protobuf-java-3.19.4.jar
s3://kumo-databricks-public/databricks-jars/scalapb-runtime_2.12-0.11.11.jar
s3://kumo-databricks-public/databricks-jars/sst_source_0.0.1.jar do aws s3 cp —no-sign-request “$u” . done After running this command, you should have all five .jar files locally.
Step 2: Upload the JARs to a Unity Catalog Volume
- In the Databricks workspace, navigate to Catalog.
- Select (or create) a Volume under the desired catalog and schema.
- Upload the downloaded .jar files into that Volume.
/Volumes/<catalog>/<schema>/<UC_volume>/kumo-jars/
Step 3: Allowlist the JAR Path in Unity Catalog Before Databricks can use these JARs on shared or all-purpose clusters, you must allowlist the Volume path:
- Go to Catalog.
- Click Settings.
- Open the Allowed JARs tab.
- Add the UC Volume path that contains the uploaded JARs.
Step 4: Attach the JARs to Your Cluster
- Go to Compute.
- Select your all-purpose cluster.
- Open the Libraries tab.
- Click Install New → JAR.
- Provide the full UC Volume path for each JAR file.
Grant Additional Permissions to Kumo Service Principal
Part of the compute pushed down by Kumo requires additional permissions to execute in your Databricks all-purpose cluster. Specifically, thespark_partition_id built-in function requires the following step:
Open Databricks SQL editor and execute the following query:
SERVICE_PRINCIPAL_ID should be replaced with the client ID of the Kumo service principal created above.
Databricks PrivateLink Requirements
Add the following IP addresses to your allowlist to enable Kumo VPC communication with your Databricks workspace.- us-west-2 region
- us-east-1 region
Data Sharing for Unity Catalog Volume
Kumo engineers helping to onboard your use cases may require temporarily access to the data generated by Kumo in your UC Volume. The data stored in your UC Volume is intermediate data generated by Kumo that does not contain raw data of the tables shared with Kumo. You should therefore create a dedicated UC Volume for usage by Kumo to facilitate sharing data in these cases. Databricks provides this sharing capability via Delta Sharing. When Kumo requests sharing of the data, you can follow these steps to temporarily grant access to the data in your UC Volume, and revoke the access afterwards.- Enable Delta sharing for your metastore if not already enabled
- Add Kumo as a Delta sharing recipient. Kumo is a Databricks recipient, and our recipient ID is
aws:us-west-2:b7ab6fd5-7ee2-4fee-853c-d4e3716c4c01 - Create a Delta sharing object for the UC Volume to be shared with Kumo.
- Kumo’s access to the UC Volume can be managed from Databricks.