1. Architecture and isolation
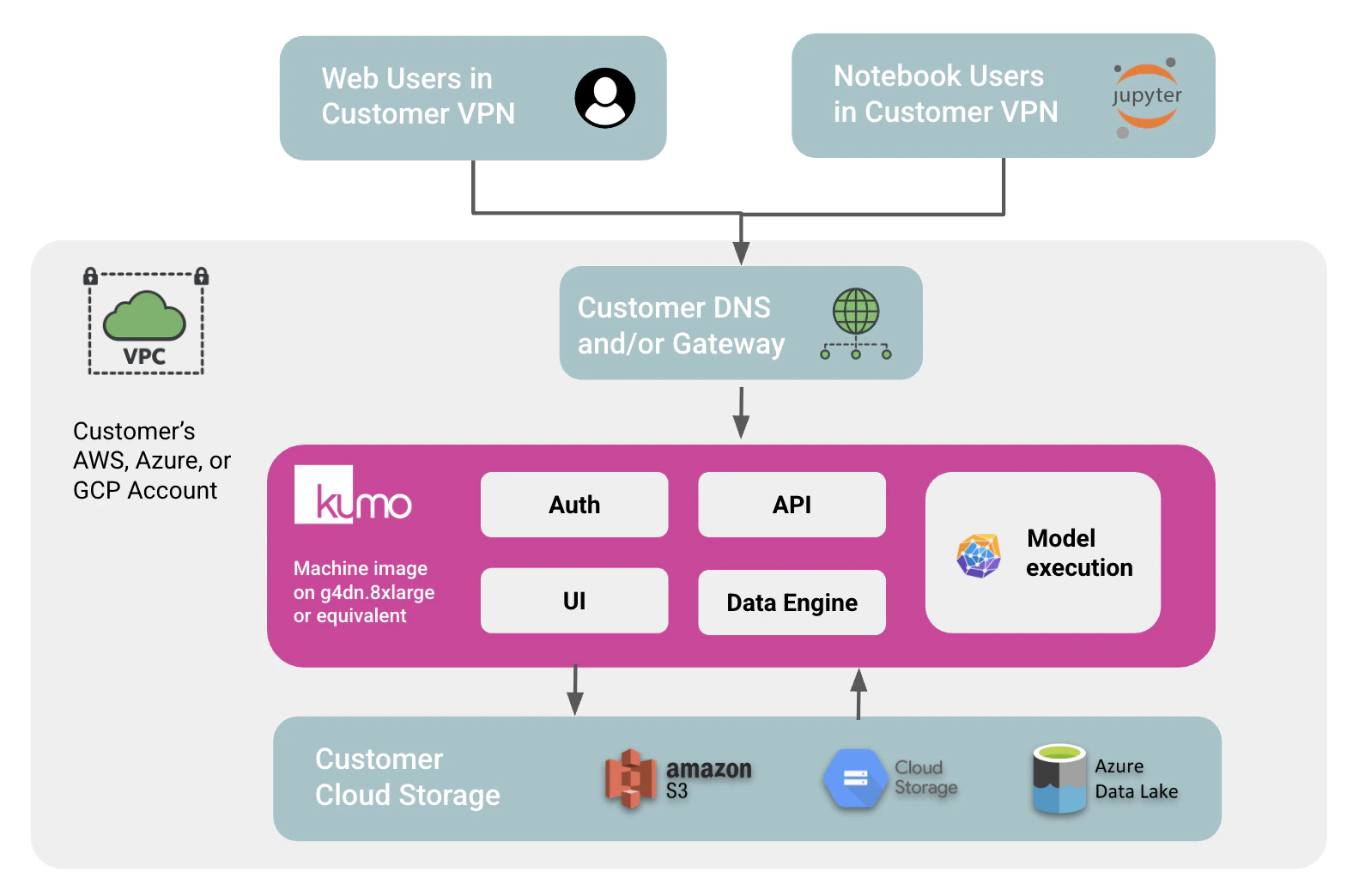
The simplified VPC deployment runs as a single Kumo machine image in your cloud account:- Kumo services run inside your VPC/VNet on a GPU instance, such as
g4dn.8xlargeon AWS or an equivalent instance on Azure or Google Cloud. - The image includes the Kumo UI, API, authentication layer, data engine, and model execution components needed for a POC workflow.
- Customer users access Kumo through your private network path, typically through corporate VPN, private DNS, and a customer-managed gateway or load balancer.
- Customer cloud storage, such as S3, Google Cloud Storage, or Azure Data Lake Storage, is the only data source and destination.
2. What this deployment supports
The simplified VPC deployment is intended to prove out Kumo’s modeling capabilities with minimal infrastructure setup:- Full Kumo model training, evaluation, prediction, and embedding workflows, sized to the selected GPU instance.
- Parquet input from customer-owned object storage.
- Output writes back to customer-owned object storage, including model binaries, predictions, embeddings, logs, intermediate artifacts, and automatic database backups.
- Private UI and API access over HTTP from the container. A customer-managed gateway or load balancer should terminate TLS using your corporate certificate.
- SDK access from employee-managed notebooks or development environments that can reach the private Kumo endpoint.
- Optional username/password authentication. For the fastest POC setup, the deployment can also be run without authentication when access is already restricted by the private network boundary.
3. Customer prerequisites
An administrator with the appropriate cloud permissions should be able to set up the simplified VPC deployment in less than an hour. The main prerequisites are:-
GPU instance
Select an appropriately sized GPU instance for the dataset and evaluation workload. On AWS,
g4dn.8xlargeis a safe default, but it can be sized up or down based on the planned data size. Use equivalent GPU instances on Azure or Google Cloud. The attached SSD should be at least 2x larger than the planned dataset used for modeling. - Kumo machine image Kumo shares the machine image into your AWS, Azure, or Google Cloud account. Your administrator launches the image in the target VPC/VNet.
- Object storage access Attach an IAM role, service account, or managed identity that can read Parquet input data from the selected S3, Google Cloud Storage, or Azure Data Lake Storage location. The same identity also needs write access to an output location for model artifacts, predictions, embeddings, logs, intermediate artifacts, and backups.
- Private network access Configure private DNS and a gateway or load balancer, such as an ALB on AWS or the cloud equivalent, so employees on the corporate network can reach the deployed Kumo UI and API without using the public internet. The container exposes HTTP; the gateway should perform SSL termination with your corporate certificate.
- SDK access for notebook users Employees can use their own Jupyter notebooks or development environments against the private Kumo API endpoint. The Kumo SDK is available on PyPI, so restricted environments may need to mirror the SDK into an internal package repository before use.
4. Estimated infrastructure cost
The simplified VPC deployment runs on a single GPU instance, so infrastructure cost is mostly driven by the selected instance size and how long the instance is left running. The following estimates use AWSg4dn on-demand Linux pricing in us-east-1 as a reference point; Azure, Google Cloud, and other AWS regions will vary. Storage, load balancer, data transfer, object storage, and support costs are not included.
| Reference instance | Best fit | Approx. hourly cost | 24/7 monthly compute | Business-hours monthly compute |
|---|---|---|---|---|
g4dn.4xlarge | Smaller POCs and sampled datasets | $1.204/hr | ~$879/month | ~$212/month |
g4dn.8xlarge | Safe default for most POCs | $2.176/hr | ~$1,588/month | ~$383/month |
g4dn.16xlarge | Larger datasets or faster iteration | $4.352/hr | ~$3,177/month | ~$766/month |