Kumo allows you to create tables by uploading Parquet or CSV files directly from your local machine, or from a cloud storage that your local machine can access (S3, GCS, Azure Blob/ADLS). This method bypasses connector setup and goes straight to table creation.
Uploading a Local File
You can upload files of up to 1GB directly from the Kumo Web Interface.
-
Navigate to Tables in the side menu and click Add Table.
-
Select Local Upload from the Source drop-down menu.
-
Drag and drop your file, or click Browse to select a file from your computer.
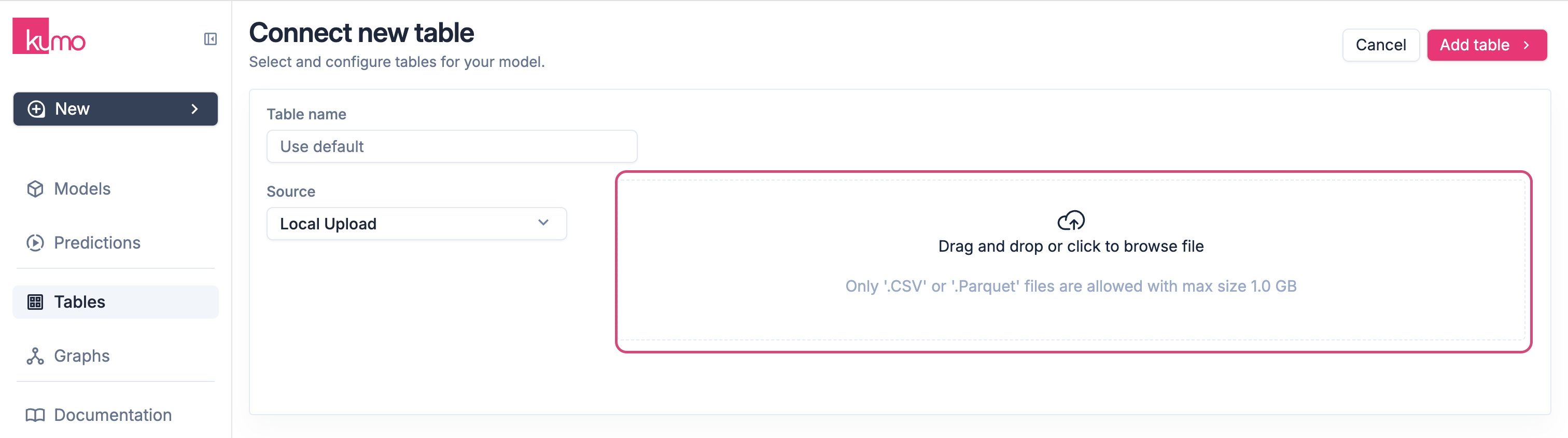
Note: CSV files must contain more than one column.
-
Click Upload to start the file upload process.

-
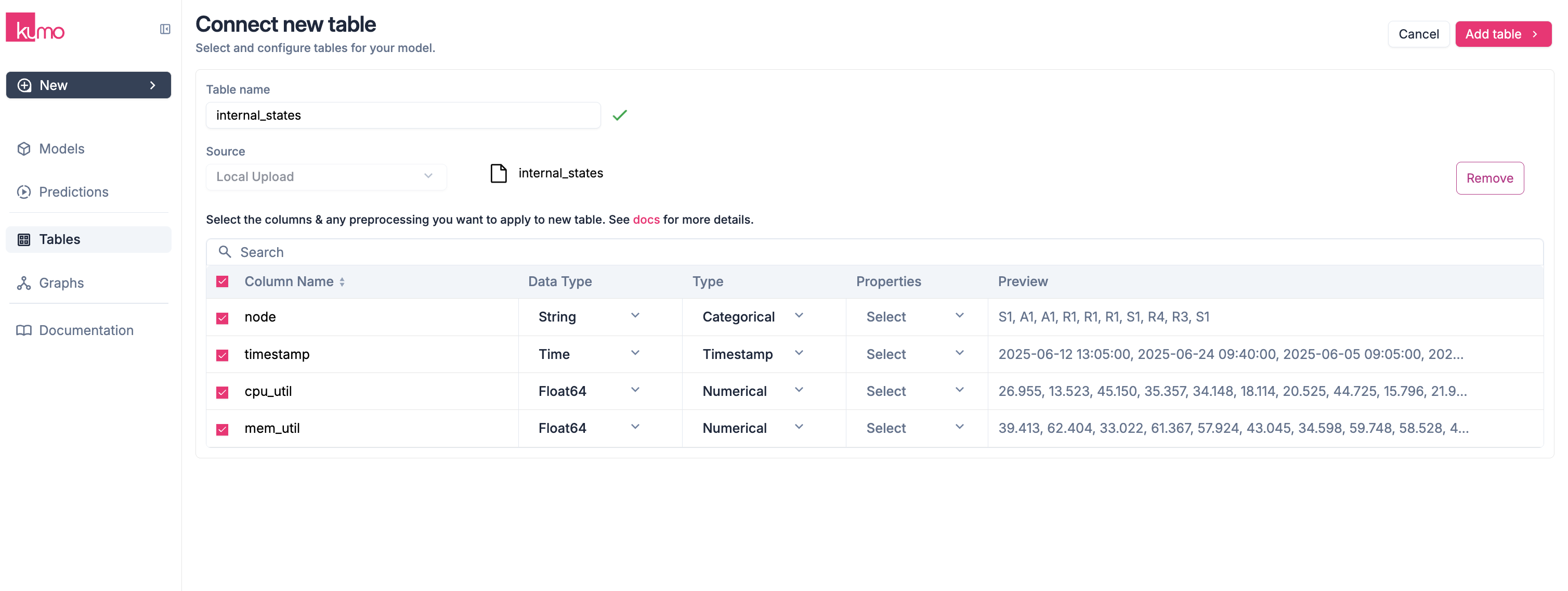
Once the upload is complete, Kumo will display the table’s columns and preprocessing options.
-
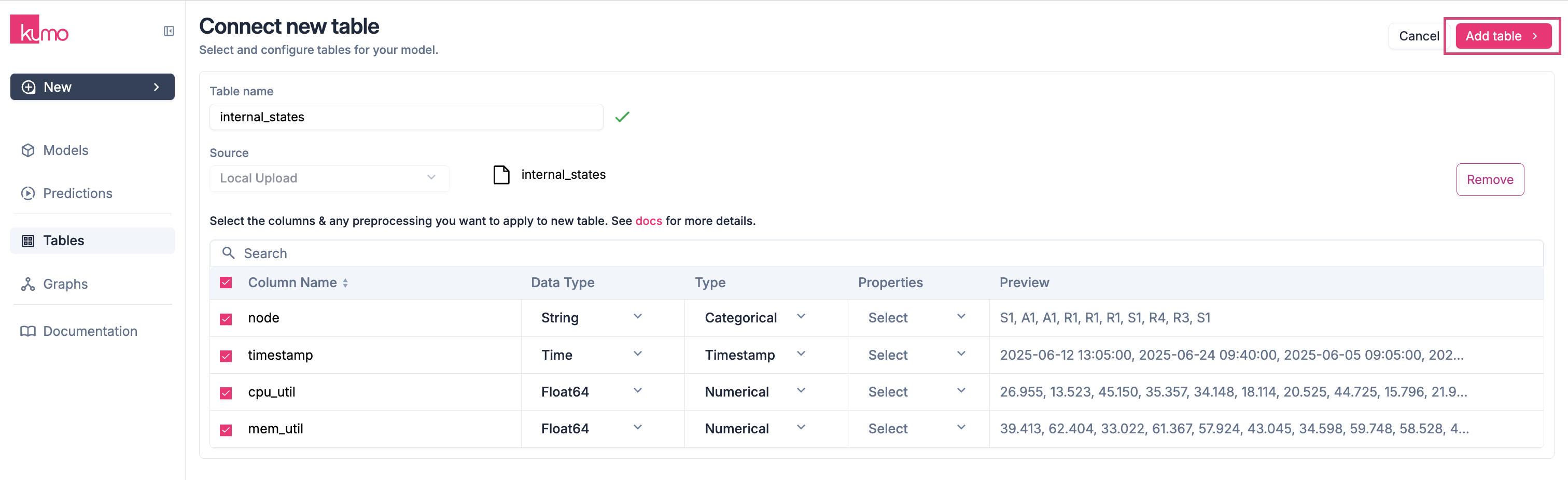
Click Add Table to finalize your table.
Upload via SDK (FileUploadConnector)
Use the SDK when you want to automate uploads, handle datasets up to 300GB in size, or upload from cloud storage (S3, GCS, Azure Blob/ADLS).
Quick examples
Local file system (single file)
Partitioned S3 directory (sharded dataset)
Capabilities
- Accepts Parquet or CSV; choose the format when constructing the connector.
- Supports single-file uploads up to 1GB.
- Supports sharded Parquet/CSV directory uploads up to 300GB (local paths or cloud prefixes).
- Remote paths supported:
s3://, gs://, abfs://, abfss://, az://.
- Directory uploads are treated as a dataset: Kumo discovers shards under the prefix and ingests them as one logical table.
- All shards within a directory must have the same schema (aligned columns and types).
- Column names must only contain alphanumeric characters (no spaces or punctuation).
- Tables are addressable via
connector["table_name"] once uploaded.
See the full SDK reference for options and behaviors: FileUploadConnector docs.