




Foundation Models (FMs) have completely taken over unstructured data domains like natural language and images, delivering significant advances in performance across tasks with little to no task-specific training. Yet structured and semi-structured relational data, which represent some of the most valuable information assets, largely miss out on this AI wave. To use AI on relational data, practitioners still use conventional machine learning approaches and build per-task and per-dataset specific models that require significant development and tuning time.
We present KumoRFM, a Relational Foundation Model (RFM) capable of making accurate predictions over relational databases across a wide range of predictive tasks without requiring data or task-specific training. KumoRFM extends principles of in-context learning to the multi-table relational graph setting. The model employs a table-invariant encoding scheme and a novel Relational Graph Transformer to reason within arbitrary multi-modal data across tables.
Through extensive evaluation on the RelBench benchmark, covering 30 predictive tasks across seven domains, we show that, on average, KumoRFM outperforms both the de-facto gold-standard of feature engineering as well as end-to-end supervised deep learning approaches by 2% to 8% across three different task types. When fine-tuned on a specific task, KumoRFM can improve its performance further by 10% to 30% on average. Most importantly, KumoRFM is orders of magnitude faster than conventional approaches that rely on supervised training.
Relational Foundation Models (RFMs)
Relational data is typically stored as structured tables in data warehouses and represents entities such as user records, transaction histories, supply chain interactions, product catalogs, financial ledgers, and health records. This data is commonly used for predictive questions like: "Is a given transaction fraudulent?", "What item is a user likely to interact with next?", "Will a user discontinue service?", or "What will be the sales of a product next quarter?"
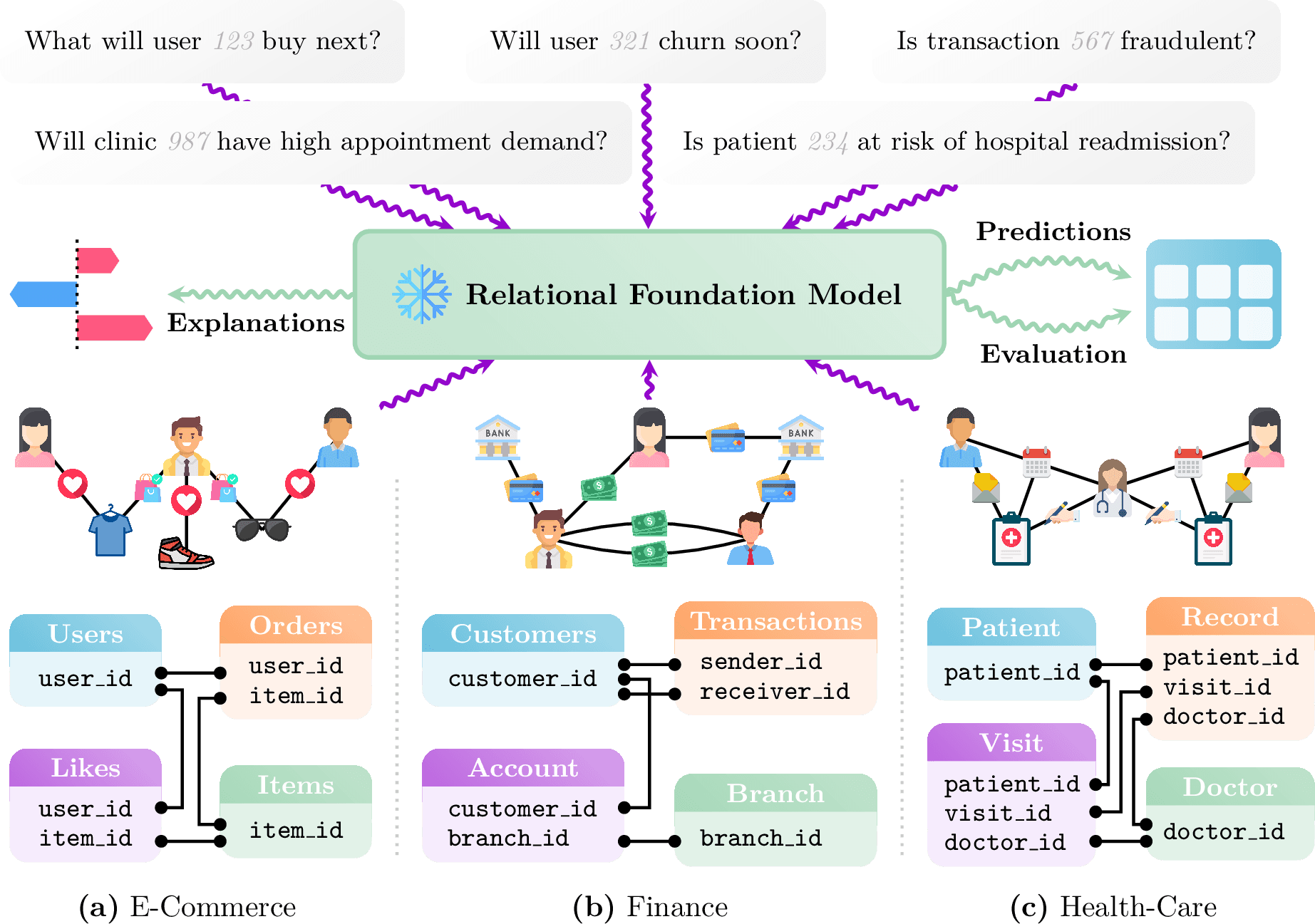
Creating a foundation model for relational data presents unique challenges. Such a model needs to effectively learn across complex database schemas with an arbitrary number of tables and columns and handle the inherent heterogeneity of column types, which often have divergent semantic meanings. Several open questions had to be addressed:
- What should a foundation model for relational data be capable of?
- Can it generalize to new databases and tasks it has never been trained on?
- Can it provide accurate predictions from a few in-context examples?
- What architectural design is necessary to handle relational complexity?
- What data is needed to train such a model effectively?
What is KumoRFM?
KumoRFM is a foundation model built for predictive tasks on structured, relational data, and draws from two key research areas: representation learning over relational databases and the emerging field of foundation models for structured data.
KumoRFM accepts as input a query written in a domain-specific language called Predictive Query Language (PQL), which is similar in syntax to SQL but focused on defining prediction problems rather than data manipulation operations.

Each PQL query defines the target variable to predict, the set of entities for which predictions should be made, and any filters or aggregation functions (e.g., FIRST, COUNT, SUM, LIST_DISTINCT). Supported tasks include regression, binary classification, multi-class and multi-label classification, and link prediction. Once a query is submitted, KumoRFM retrieves relevant data from the underlying relational database and automatically generates context examples—labeled subgraphs that capture the relationships and historical patterns relevant to the prediction task. These are then used by the model to reason about the current query.
The system does not require task-specific training. Instead, it applies in-context learning at inference time by sampling from the historical data stored in the database. This allows it to handle new datasets or tasks without retraining the underlying model.
KumoRFM Under the Hood: Architecture and Design
KumoRFM operates on relational databases by internally converting them into temporal, heterogeneous graphs. Each table in the database is treated as a distinct node type, and rows in the tables become nodes. Foreign key relationships define the edges between nodes. Each node can carry multi-modal information such as numerical values, categories, timestamps, text, or vector embeddings.
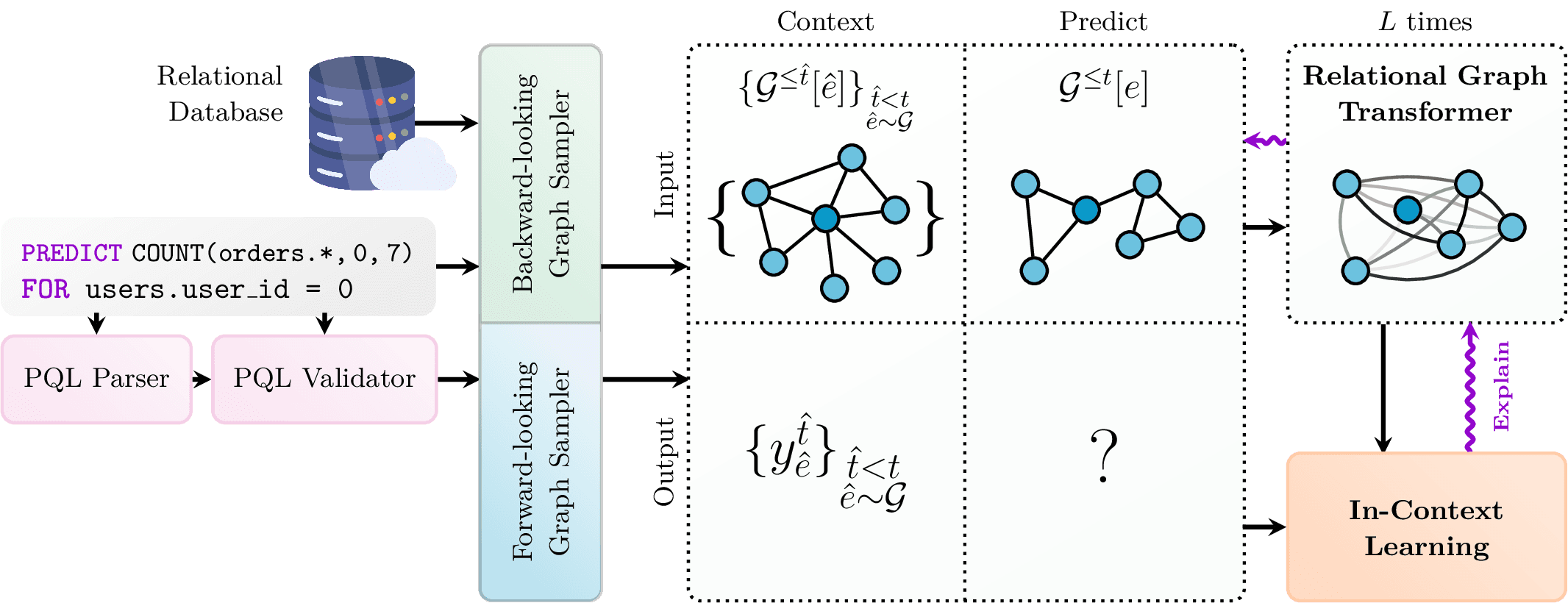
The model architecture consists of several key components:
- A powerful real-time in-context label generator that dynamically curates task-specific context labels for any entity at any point in time.
- A novel pre-trained Relational Foundation Model that seamlessly integrates a table-width invariant column encoder and performs table-wise attention mechanisms. Here, each cell in every table is transformed into a dense vector representation, based on the semantic type of the column (e.g., numeric, categorical, timestamp). Afterwards, a Relational Graph Transformer performs attention within the graph using positional encodings for node types, temporal information, structural proximity (e.g., hop distance from the anchor node), and local subgraph patterns. This step enables the model to integrate information across related tables.
- For each prediction, KumoRFM samples a set of context examples—historical subgraphs with known labels—and encodes them alongside the test subgraph. The in-context learning module uses these examples to condition the model’s prediction without any supervised training requirements.
- A comprehensive explainability module that leverages both analytical and gradient-based techniques to provide explanations at the global data level as well as for individual entities.
- For production-scale deployments or high-throughput tasks, KumoRFM supports fine-tuning. In these cases, the pre-trained model can be specialized to a specific query or dataset, replacing the in-context inference mechanism with a dedicated supervised pipeline.
This architecture enables the model to work across arbitrary relational schemas, handle data heterogeneity, and support both exploratory and operational use cases without requiring manual feature engineering or custom model development.
Conclusion
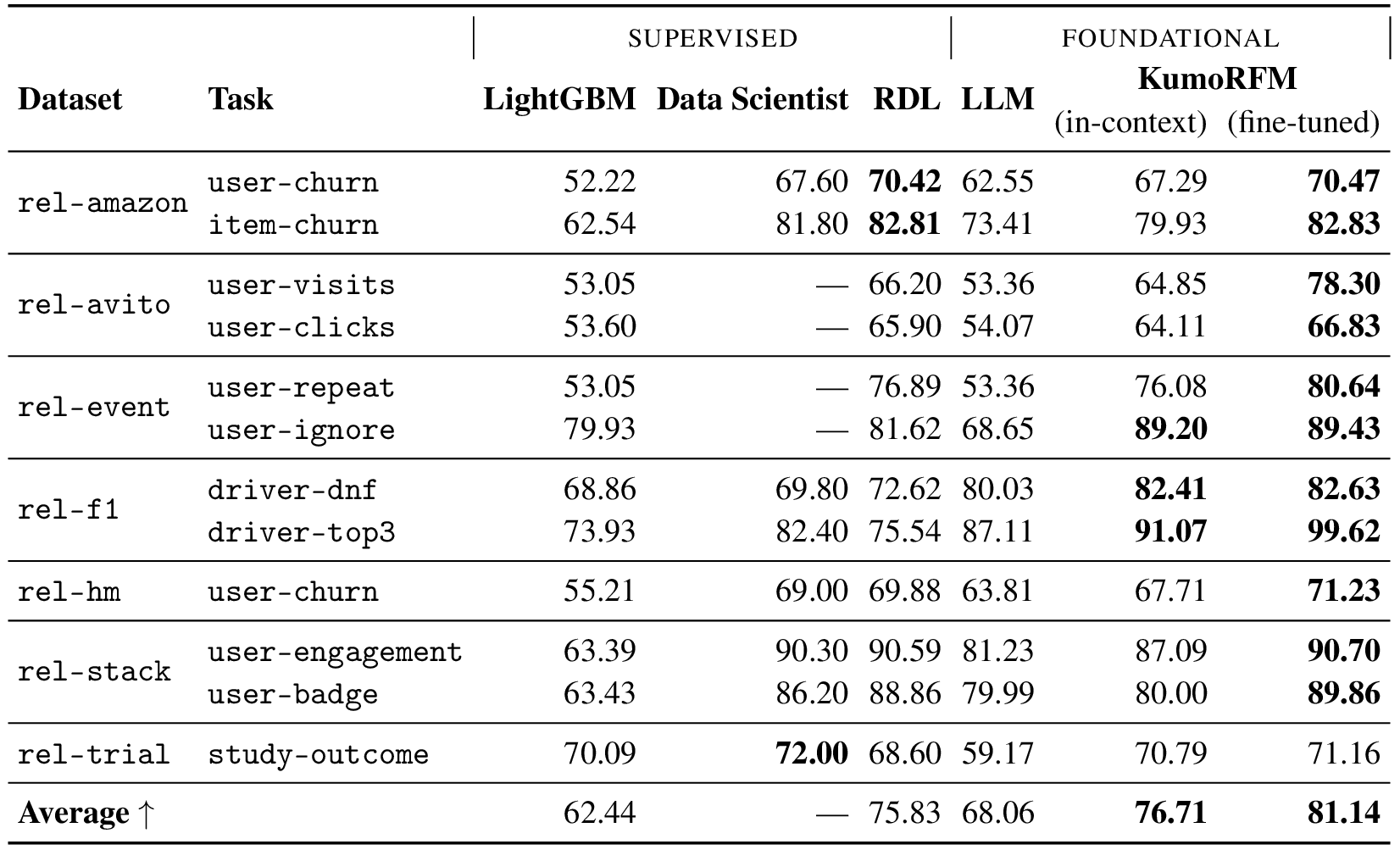
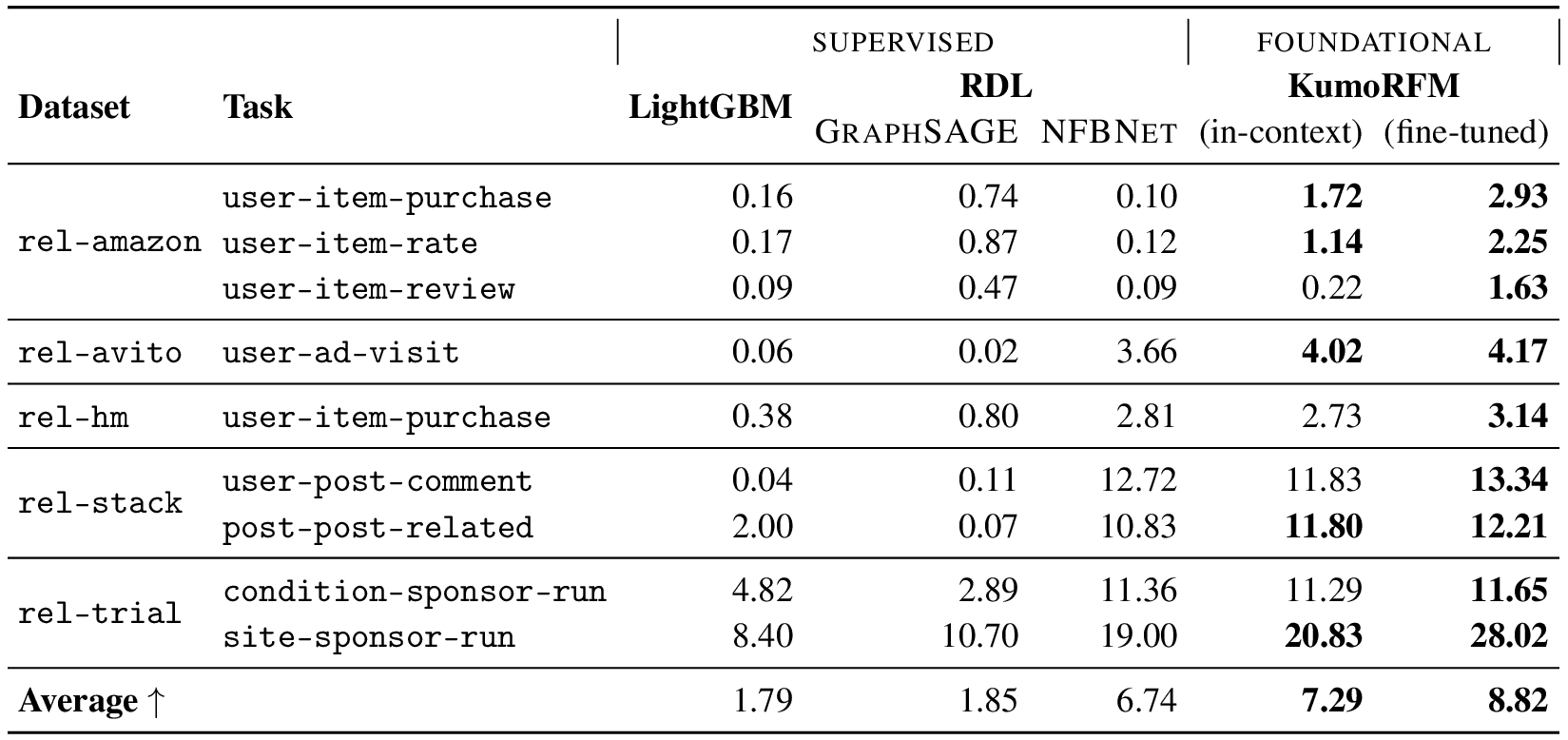
KumoRFM integrates pre-training, in-context learning, and relational graph reasoning into a unified foundation model for structured data. The benchmark results reveal several key findings: KumoRFM achieves comparable or better results than expert-engineered solutions. Notably, even without task-specific training, KumoRFM's in-context capabilities demonstrate competitive performance against supervised approaches. When fine-tuned, the model establishes new performance benchmarks on multiple classification, regression and recommendation tasks across e-commerce, social, medical, and sports domains. These results demonstrate the effectiveness of foundation models for predictive modeling on relational data.
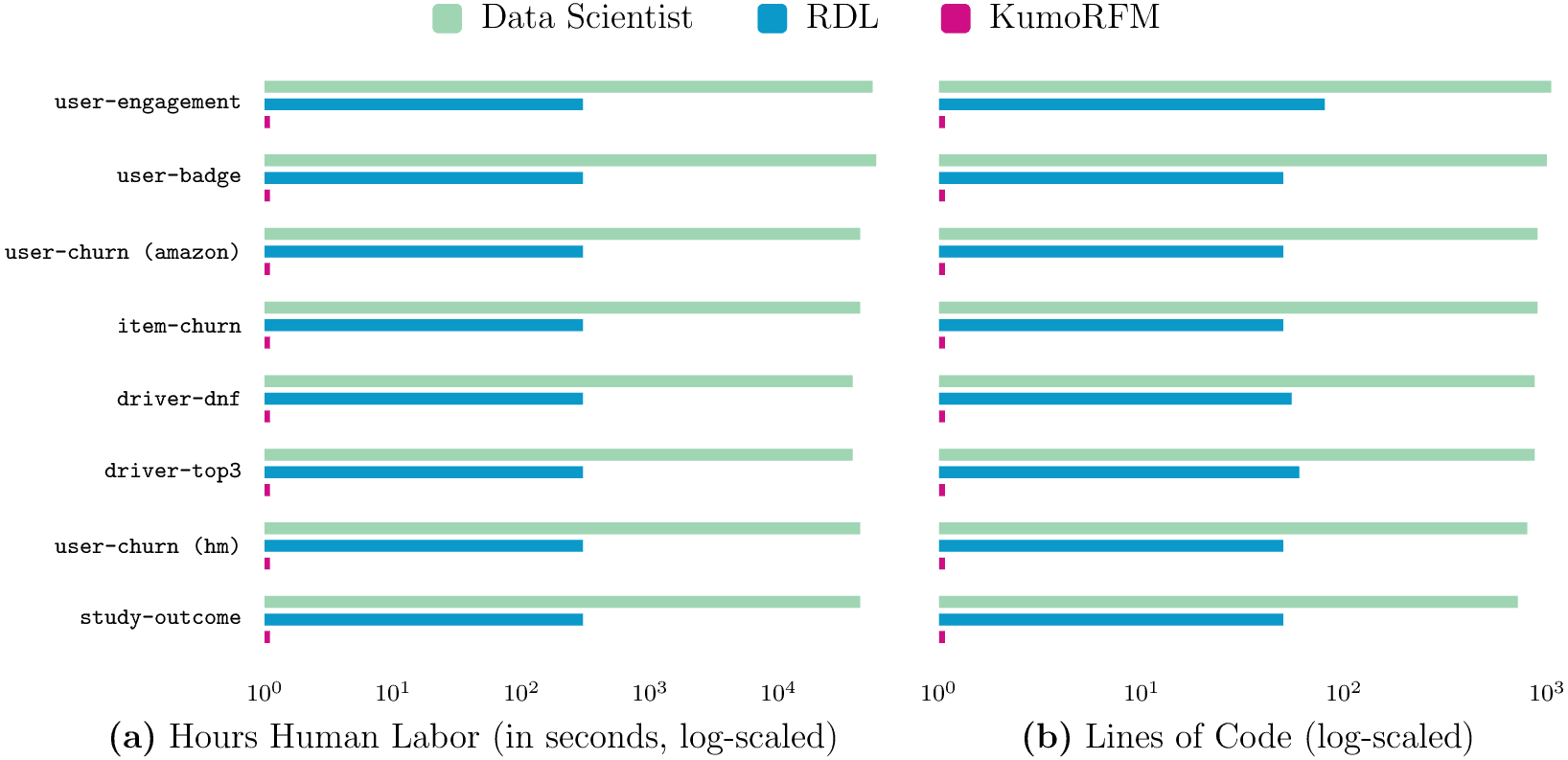
Most importantly, KumoRFM is orders of magnitude faster than conventional approaches that rely on supervised training, and provides a zero-code solution to query any entity and any target at any future point in time. These results highlight the core value proposition of a relational foundation model: enabling real-time predictions with minimal effort, paving the way for a new generation of predictive systems that can be stacked, queried, and operationalized to drive faster and smarter business decisions.
To read more about KumoRFM, you can view the full whitepaper here.
Join our community on Discord.
Connect with developers and data professionals, share ideas, get support, and stay informed about product updates, events, and best practices.