



In the world of enterprise data, the most valuable insights often lie not in individual tables, but in the complex relationships between them. Customer interactions, product hierarchies, transaction histories—these interconnected data points tell rich stories that traditional machine learning approaches struggle to fully capture. Enter Relational Graph Transformers: a breakthrough architecture that's transforming how we extract intelligence from relational databases.
Relational Graph Transformers represent the next evolution in Relational Deep Learning, allowing AI systems to seamlessly navigate and learn from data spread across multiple tables. By treating relational databases as the rich, interconnected graphs they inherently are, these models eliminate the need for extensive feature engineering and complex data pipelines that have traditionally slowed AI adoption.
This isn't just an incremental improvement—it's a fundamental rethinking of how AI interacts with business data, delivering remarkable results:
- 20x faster time-to-value compared to traditional approaches
- 30-50% accuracy improvements through deeper understanding of relational context
- 95% reduction in data preparation effort
In this post, we'll explore how Relational Graph Transformers work, why they're uniquely suited for enterprise data challenges, and how they're already revolutionizing applications from customer analytics and recommendation systems to fraud detection and demand forecasting.
Whether you're a data scientist looking to push the boundaries of what's possible, or a business leader seeking to unlock the full potential of your organization's data assets, Relational Graph Transformers represent a powerful new tool in your AI toolkit.
This post is part of a series about Graph Transformers. If you want to learn more about Graph Transformers in the wild, see our previous post “An Introduction to Scalable Graph Transformers”.
From Relational Database to Graphs
Relational databases are one of the most common data formats in the world, especially in business settings. They store information in a structured format across multiple tables, with foreign key relationships defining how entities in one table relate to those in another. While traditional ML models often struggle to extract meaningful patterns from such multi-table setups, Relational Deep Learning re-frames the problem: instead of flattening tables into feature vectors, we transform the entire database into a graph—a format much more expressive for learning complex relationships.
Let’s break this transformation down step by step.
Step 1: Understanding the Relational Database
We start with a database defined by a set of tables and a set of links that describe foreign key relationships between tables. Each link indicates that a foreign key in one table points to the primary key in another.
Each row in a table is treated as an entity with four components:
- A primary key that uniquely identifies it.
- A set of foreign keys linking it to rows in other tables.
- A set of attributes containing its descriptive content (e.g., name, price, image).
- An optional timestamp if the row records an event over time.
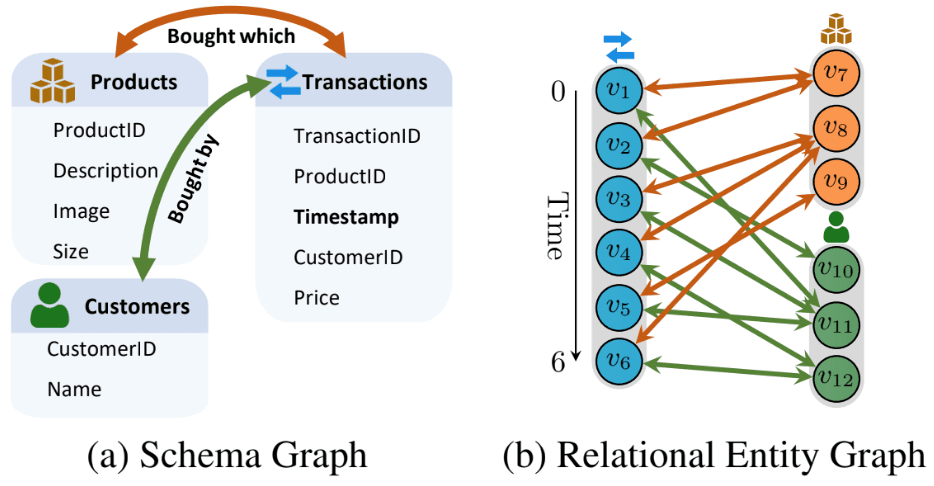
Step 2: Creating the Schema Graph
Before jumping to the entity-level graph, we first construct a schema graph—a high-level blueprint of the database. In this graph, nodes are tables, and edges represent foreign key relationships (and their inverses), ensuring every table is reachable. This schema graph helps define the types of nodes and edges that will appear in the next step: the entity graph.
Step 3: Building the Relational Entity Graph
Now, we construct the relational entity graph, where:
- Each node corresponds to a row (entity) in the database.
- Each edge connects entities based on foreign key links.
This graph is heterogeneous: each node and edge is typed based on the schema graph, allowing models to distinguish between, say, a Customer node and a Product node, or between a purchased edge and a viewed edge.
By turning the relational database into a richly structured graph, we enable deep learning models to reason directly over the underlying relationships—without flattening, joins, or feature engineering. This transformation preserves the semantics of the original data, respects its structure, and supports heterogeneous and temporal modeling out of the box.
This is the foundation on which Relational Graph Transformers operate: a graph-native, schema-aware, and modality-flexible input space that unlocks the full expressive power of deep learning for relational data.
Relational Graph Transformers
Graph Transformers have gained traction in research, particularly for applications like molecular modeling, where graphs are relatively small and structured. However, their adoption in large-scale, real-world industrial settings remains limited. Deploying standard Graph Neural Networks at scale is already a significant challenge, and Relational Graph Transformers introduce additional complexity, both in terms of computational cost and scalability. At Kumo, we have engineered Relational Graph Transformers to work seamlessly on massive relational datasets—where graphs contain millions of nodes and billions of edges—unlocking their potential beyond small molecule graphs and into enterprise-scale AI applications.
Among the many AI models that Kumo offers, Relational Graph Transformers stand out for their ability to capture complex relationships in relational data. Unlike traditional models that struggle with multi-table structures, Relational Graph Transformers excel at understanding intricate connections between entities, even when they are not directly linked. By leveraging attention mechanisms, they can efficiently model long-range dependencies, making them particularly powerful for predictions that require information from multiple, interconnected sources.
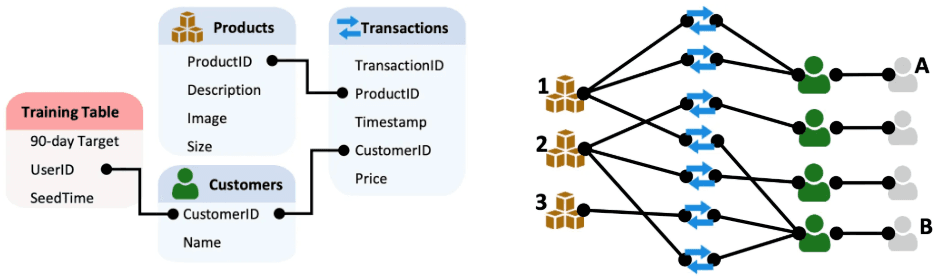
For example, imagine an e-commerce database with three tables: Products, Customers, and Transactions. In a traditional relational setup, a customer's interactions are mostly limited to their direct transactions, forming a structured but somewhat constrained view of relationships. If we use a standard message-passing GNN, transactions are always two hops away from each other, connected only through the shared customer. This means that transaction-to-transaction interactions are indirect and require multiple layers of message passing to propagate information. Furthermore, products would never directly interact with each other in a two-layer GNN, since their messages would have to pass through both a transaction and a customer, making long-range dependencies difficult to capture. This structural limitation can hinder the model’s ability to recognize complex relationships that extend beyond immediate connections.
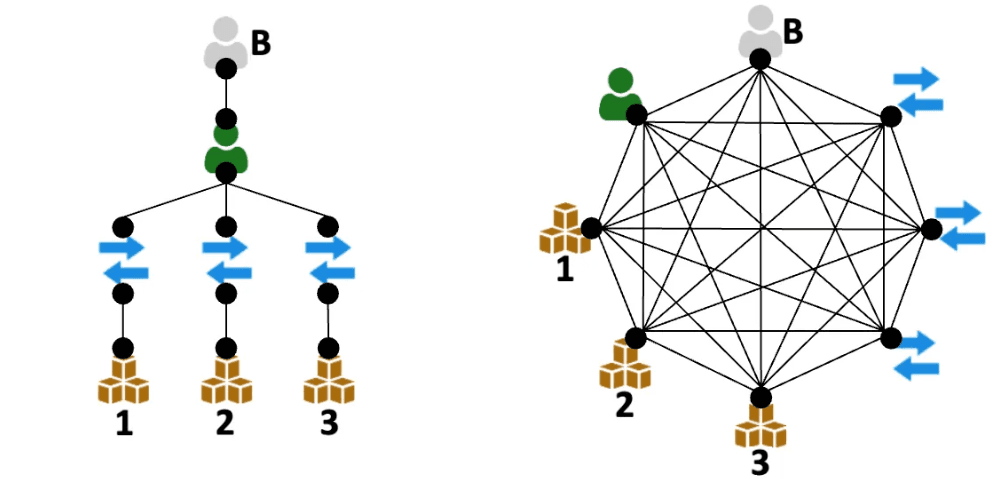
A Relational Graph Transformer, on the other hand, sees the data as a fully connected graph, allowing every node to directly interact with any other. This means that transactions can now exchange information without needing to pass through the shared customer, overcoming the two-hop limitation of standard message passing. Similarly, products are no longer isolated from each other, since they can directly attend to other products, transactions, or customers, capturing more complex relationships. By leveraging attention mechanisms, the model dynamically weighs the importance of these distant connections, uncovering insights that would be harder to capture with sequential message-passing approaches. This holistic perspective enables richer, more accurate predictions, making Graph Transformers particularly powerful for relational data.
Adapting Graph Transformers for Relational Data
Relational databases present a unique challenge for deep learning models: they contain rich, interconnected information spanning multiple tables with complex relationships that can't be easily flattened into simple feature vectors. While generic Graph Transformers have shown remarkable capabilities in handling graph-structured data, adapting them specifically for relational databases requires thoughtful architectural modifications to preserve and leverage the inherent structure of relational data.
In this section, we'll explore how Graph Transformers can be adapted specifically for relational data, examining the key architectural considerations and modifications needed to create effective Relational Graph Transformers. We'll compare traditional and relational graph transformer approaches along several critical dimensions. By understanding these adaptations, we can better appreciate how Relational Graph Transformers offer a powerful framework for learning directly from relational data without extensive feature engineering or data restructuring.
Relational Graph Connectivity
A key difference between a standard Graph Transformer and a Relational Graph Transformer lies in how they handle graph connectivity of relational tables. A traditional Graph Transformer treats its input as a fully connected graph, where every token (or node) can directly attend to every other token. While this global attention mechanism is powerful, it does not leverage any inherent structural information present in real-world graphs. Additionally, when dealing with large datasets containing millions or billions of nodes, maintaining full connectivity quickly becomes computationally infeasible.
On the other hand, a Relational Graph Transformer introduces an inductive bias by incorporating the relational graph’s topology into the attention mechanism. Instead of allowing every node to attend to all others, nodes primarily focus on their local neighbors, similar to Graph Neural Networks (GNNs). This localized attention reduces computational costs while ensuring that the model respects the graph structure. By balancing global attention with local connectivity, Relational Graph Transformers efficiently capture both long-range dependencies and fine-grained relational patterns, making them well-suited for large-scale graph datasets.
Handling Multi-modal Relational Node Attributes
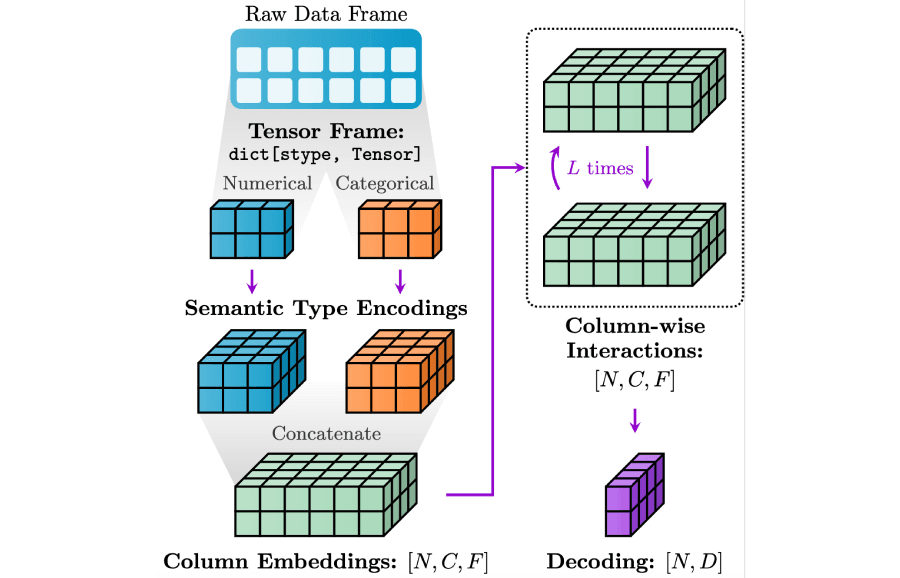
In a traditional Text Transformer, the input is a sequence of tokens drawn from a fixed vocabulary, this is, a well-defined and closed set (e.g., words or subwords). Each token has a corresponding embedding, and the model processes the sequence using self-attention layers. In Graph Transformers, the setup is often more flexible. Instead of tokens, each node is typically initialized with a feature vector or a precomputed embedding, for example, based on metadata, spatial coordinates, or learned representations from prior tasks. But when working with relational tables, this idea breaks down completely. A row in a table isn’t a clean sequence of tokens, it’s a collection of heterogeneous features, which may include numerical values, categorical labels, timestamps, free-form text, or even images. There is no fixed “vocabulary” to draw from, and each column may live in a different modality space.
To transform such data into dense node embeddings suitable for graph-based learning, one needs to follow a multi-modal encoding pipeline:
- Modality-Specific Embeddings: Each column is first embedded according to its data type:
- Numerical features might be normalized and passed through MLPs.
- Categorical variables are typically embedded using learnable embedding tables.
- Text fields are encoded with pre-trained language models like Sentence-BERT, or any other foundation model.
- Image data can be processed using pre-trained CNNs or vision transformers.
- Timestamps can be treated as categorical, continuous, or cyclic features depending on granularity.
- Fusing Attribute Embeddings: Once each attribute is encoded, a deep tabular model (e.g., based on attention or MLPs) fuses all the embeddings into a single vector per row. This embedding captures the entire row’s identity — much like a sentence embedding in NLP, but drawn from multiple modalities.
- Relational Integration via Graphs: These fused embeddings then act as node features in a graph built from the relational structure. A Relational Graph Transformer can now processes this graph, updating each node’s embedding by exchanging messages with its neighbors, enabling relational reasoning across entities.
- End-to-End Learning: Crucially, the entire pipeline — from column-level encoding to row fusion and graph message passing — can be trained jointly. This allows the model to learn both how to represent heterogeneous attributes and how to incorporate relational structure for the downstream task.
Compared to text transformers, this setup must handle far more diverse input spaces, which makes modularity and flexibility essential. To support this complex pipeline, an option is to adopt PyTorch Frame, a PyTorch-based framework designed for deep learning over multi-modal tabular data. By using PyTorch Frame, one is able to streamline the entire process — from raw relational data to graph-based representation learning — while maintaining modularity, scalability, and compatibility with the broader PyTorch ecosystem.
Relational Edge Awareness
In standard Transformers, the attention mechanism treats all connections equally, with no explicit edge features. This works for sequential data like text, but falls short for relational databases where edges carry crucial semantic meaning. In these databases, an edge might represent a "purchased" relationship between customer and product, a hierarchical "reports-to" connection, or various other typed relationships defined by the schema.
Relational Graph Transformers address this limitation by incorporating edge information directly into their architecture. They employ relation-aware attention mechanisms with specialized weights for different edge types, sometimes restricting attention flow based on foreign key constraints. By respecting the database schema as a structured blueprint of domain knowledge, Relational Graph Transformers turn what would be lost information in generic approaches into valuable learning signals. This awareness of edge semantics proves particularly powerful in applications like customer analytics, fraud detection, and supply chain optimization, where different relationship types carry distinct business implications.
Leveraging relational edge awareness and the ability to handle multi-modal relational node attributes, relational graph transformers demonstrate a powerful capacity to effectively process complex heterogeneous graphs, such as the relational entity graphs. This nuanced understanding of both node features and edge relationships enables them to capture the rich and diverse information present in such intricate structures.
Time Encoding
Many real-world applications of Relational Deep Learning involve temporal events—customer transactions, sensor readings, or user interactions—that unfold over time. To preserve this natural progression, time embedding can be used. These embeddings serve as a positional encoding for the Relational Graph Transformer, allowing it to understand when each node appeared in the graph and incorporate the time dimension into its predictions.
Scaling Considerations
Building on our previous discussion of scaling challenges for generic Graph Transformers, Relational Graph Transformers face additional considerations when operating on enterprise-scale relational databases. While the fundamental quadratic complexity challenge remains, the relational context introduces unique complications worth highlighting.
Relational databases in production environments frequently contain high-cardinality tables with millions of rows—customer transactions, log entries, or sensor readings—resulting in graphs with millions of nodes and potentially billions of edges. To make Relational Graph Transformers feasible for such large relational graphs, one can leverage sampling or batching strategies that are specifically tailored for the structure of relational data. Instead of applying a generic self-attention mechanism across the entire graph, which would be computationally prohibitive for relational data, Relational Graph Transformers break down the graph into subcomponents based on the schema. By focusing on smaller, manageable subgraphs at a time, they can significantly reduce the computational burden associated with large relational datasets, enhancing scalability and reducing the computational overhead.
Furthermore, unlike generic Graph Transformers, which are typically benchmarked on simpler academic datasets like citation networks or social graphs, Relational Graph Transformers are purpose-built to handle the complexity of real-world relational databases. These systems are optimized for tasks like churn prediction, fraud detection, and recommendation, which are common in enterprise settings. Thus, they must also prioritize prediction speed, cold-start generalization, and resilience to data sparsity, making them well-suited for the practical constraints and challenges of relational database applications.
Experiments
To evaluate the effectiveness of Relational Graph Transformers, we conducted experiments comparing their performance against GNNs. By testing both models on relational datasets, we aimed to understand how well Relational Graph Transformers leverage positional information and whether they offer advantages in capturing complex relationships for predictive tasks.
Data: For our experiments, we chose RelBench, a public benchmark designed for predictive tasks over relational databases using graph-based models. RelBench provides a diverse set of databases and tasks across multiple domains, making it an ideal testbed for evaluating the effectiveness of Graph Transformers. By leveraging its structured relational data and well-defined predictive challenges, we ensure that our comparison between Relational Graph Transformers and GNNs is both rigorous and representative of real-world applications.
Setup: To ensure a fair comparison between Relational Graph Transformers and GNNs, we use neighbor sampling with two hops of 15 neighbors and set the node dimension to 128 for all models. For the GNN baseline, we evaluate four different hyperparameter configurations and report the best performance. For transformers, we experiment with three different hyperparameter sets and report the best average over two runs. In all transformer setups, we use four layers, eight attention heads, and set the feedforward network (FFN) dimension to 512 (four times the node dimension). Additionally, we also evaluate a LightGBM classifier baseline over the raw entity table features, to establish a comparison with classical Machine Learning methods. Note that here only information from the single entity table is used.
Positional Encoding
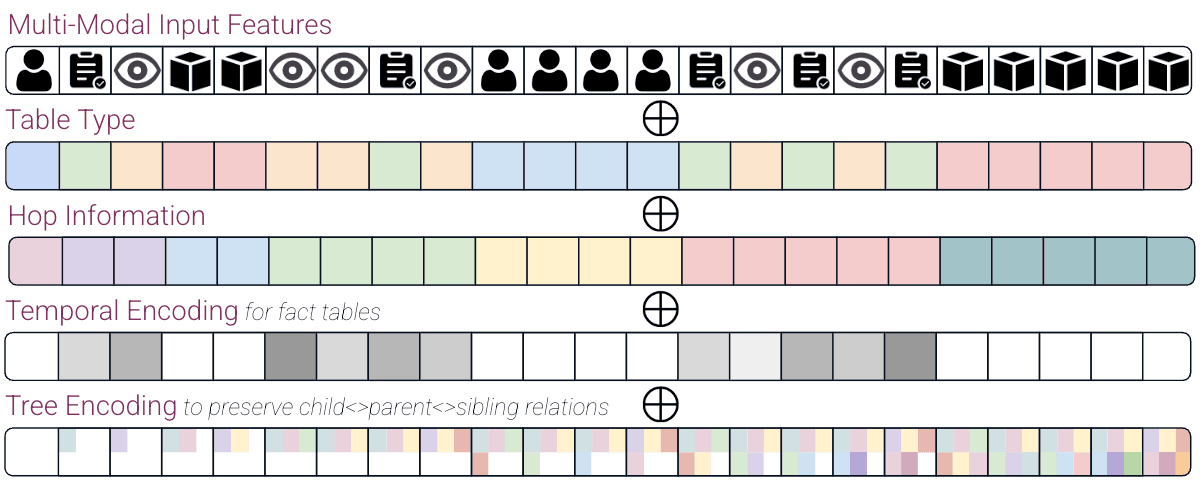
At Kumo, we work with graphs containing millions of nodes and billions of edges, making global positional encodings, such as Laplacian or Random Walk-based methods, very expensive to precompute. Instead, we focus on local positional encodings that can be efficiently derived during training, ensuring scalability without sacrificing accuracy while adapting to the dynamic nature of real-world graph data. For this reason, we employ:
- Hop encoding: they encode the distance between each node and the target entity within the subgraph, helping the transformer understand proximity relationships.
- Tree encoding: Following Shiv and Quirk (2019) & Peng et al. (2022) we employ tree-based positional encoding that preserve the inherent hierarchical parent-child relationships and overall graph topology.
- Message Passing encoding: In many research settings, global node embeddings are often computed using methods like node2vec. However, as we have discussed, precomputing such embeddings is impractical at Kumo’s scale. Instead, we approximate this idea by assigning each node a random embedding and refining it through a Graph Neural Network (GNN) that performs message passing over the original graph structure. This allows nodes to develop positional representations influenced by their neighbors, effectively capturing local topology without requiring expensive precomputations.
- Time encoding: We primarily handle temporal graphs that evolve over time, rendering static global encodings quickly outdated and potentially misleading. To preserve this natural progression, Kumo’s model ensures that nodes only receive information from entities with earlier timestamps, preventing data leakage and “time travel” issues while improving generalization across different time periods. To reinforce this temporal structure, we employ time embedding that serves as a positional encoding for the Graph Transformer.
All these positional encodings are designed to seamlessly integrate, combine, and compose with one another. By incorporating these encodings, we provide the transformer with a sense of "where" each node is located within the subgraph, enabling more structured and meaningful predictions.
Results on RelBench Datasets
The task involves predicting binary labels for a given entity at a specific seed time. Following RelBench, we use the ROC-AUC metric for evaluation, where higher values indicate better performance.
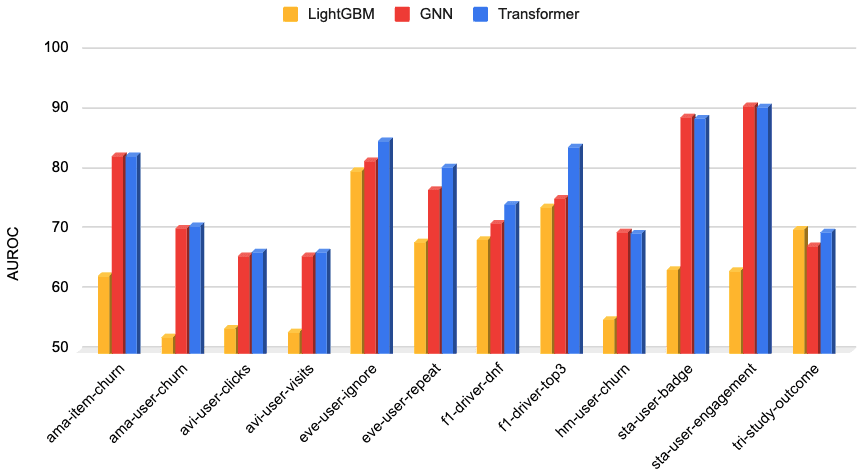
The results reveal that Relational Graph Transformers tend to outperform both baselines on several tasks, particularly in scenarios where capturing long-range dependencies is beneficial. Our experiments show that the Relational Graph Transformer delivers a significant accuracy improvement, outperforming the GNN baseline by around 10% and the LightGBM baseline by over 40%, demonstrating its effectiveness in modeling complex relational structures. Although the performance differences on some datasets—such as rel-amazon and rel-avito—are marginal, these results suggest that Graph Transformers have a competitive edge in many cases.
To ensure a fair comparison, we use 2-hop neighbor sampling for both models, employing the same local neighborhood. Even in this constrained setup, Graph Transformers already match or exceed GNN performance across most datasets and tasks. Unlike GNNs which require connectivity in the graph for message passing, Relational Graph Transformers can naturally aggregate information from distant or even unconnected nodes. This capability to leverage information beyond connected entities suggests that combining Relational Graph Transformers with diverse graph sampling techniques could further enhance their performance, presenting a promising direction for future research.
Conclusion
Our experiments show that Relational Graph Transformers consistently outperform GNNs—by around 10% on average and up to 15%—and deliver even larger gains of over 40% compared to classical machine learning baselines like LightGBM, all while enabling richer modeling of complex relational structures through long-range information aggregation beyond local neighborhoods.
A key advantage of Kumo’s implementation of Relational Graph Transformers is the flexible and composable positional encodings, which seamlessly integrate into the model. By incorporating time embeddings, hop embeddings, tree embeddings and more, we ensure that transformers can effectively capture relational structures while preserving key inductive biases from GNNs. The strong results across diverse tasks further validate this approach.
Looking ahead, there are exciting opportunities to push performance even further. Smarter neighborhood sampling strategies, enhanced global context through cross-attention, and more expressive positional encodings all represent promising research directions. Through these innovations, Kumo isn't just following the frontier of relational deep learning—we're defining it, empowering you to extract unprecedented insights from your data!
Experience the Power of Relational Graph Transformers Today—Free!
Ready to see the difference? Kumo makes it easy to get started with Relational Graph Transformers at no cost. Simply sign up for your free trial, connect your data, and watch as your first Graph Transformer model comes to life.
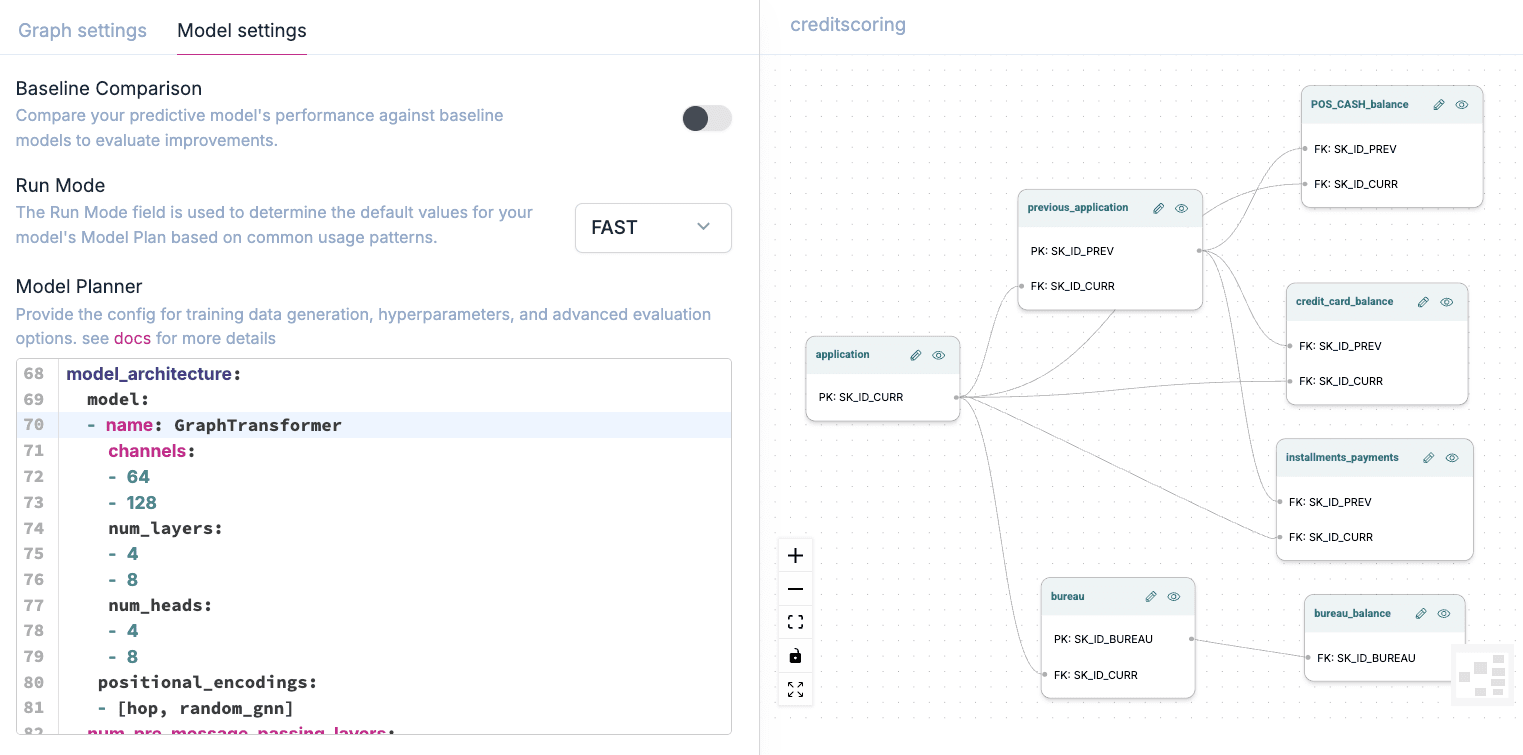
Not sure which architecture is right for your needs? Let our AutoML do the heavy lifting by automatically selecting the optimal model for your dataset and predictive queries. Start transforming your graph data insights today!
Further Reading
- Relational Deep Learning: Graph Representation Learning on Relational Databases Matthias Fey, Weihua Hu, Kexin Huang, Jan Eric Lenssen, Rishabh Ranjan, Joshua Robinson, Rex Ying, Jiaxuan You, Jure Leskovec arXiv:2312.04615
- PyTorch Frame: A Modular Framework for Multi-Modal Tabular Learning Weihua Hu, Yiwen Yuan, Zecheng Zhang, Akihiro Nitta, Kaidi Cao, Vid Kocijan, Jinu Sunil, Jure Leskovec, Matthias Fey arXiv:2404.00776
- RelBench: A Benchmark for Deep Learning on Relational Databases Joshua Robinson, Rishabh Ranjan, Weihua Hu, Kexin Huang, Jiaqi Han, Alejandro Dobles, Matthias Fey, Jan E. Lenssen, Yiwen Yuan, Zecheng Zhang, Xinwei He, Jure Leskovec arXiv:2407.20060
Join our community on Discord.
Connect with developers and data professionals, share ideas, get support, and stay informed about product updates, events, and best practices.