PQL
For more information about how to specify the Split you would like to use, refer to the documentation here.
PQL
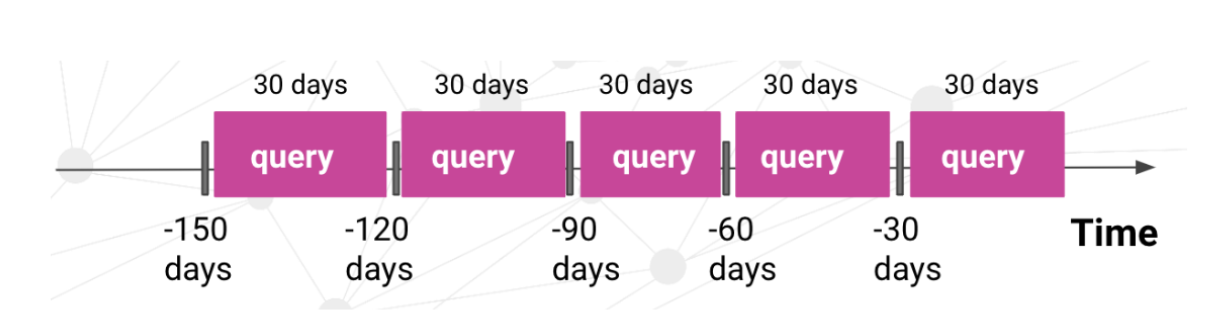
- The holdout split occurs strictly later in time than the training split.
- The training splits are balanced in size.
Example: Predicting Total Sales Over 30 Days The following Predictive Query predicts the total sales value per customer in the next 30 days:
PQL
transactions table.
For example, if your dataset spans September 20, 2018, to September 22, 2020, Kumo will:
- Compute 30-day user spend at various past time points.
- Automatically generate the appropriate sampling and training split methodology.