Churn Prediction
March 5, 2023
Kumo team

Churn and retention models are useful to identify who is likely to stop using your product or service within a specified timeframe, say within the next week or month. There’s often a sense of urgency in proactively identifying churn risk because, often, there is a disproportionate cost to re-acquiring the customer relative to re-engaging them. Improving retention early on even marginally can lead to drastic improvements in profitability, and can help you convert low-engagement customers into loyal, high-spend customers with the right approach.
Predicting churn can mean identifying high impact events, including membership cancellation, app uninstalls, unsubscribing, or deactivating. It can also be used to predict significant changes in activity that signal reduced engagement – such as declines or drops in views/clicks/purchases, or other activities.
With Kumo, you can access the power of an industry leading ML team with a simple platform, making it easy to connect your raw relational data and then make predictions using state-of-the-art models with high accuracy almost instantly.
This blog will show you how to go from raw data to actionable insights from churn and retention analytics.
Building your Graph
Your enterprise data naturally is represented by a graph – the entities include users, transactions, clicks, views, and attribute data. This graph includes the patterns and interactions between the entities that represent users, purchases, actions, and more.
Kumo lets you quickly connect your data sources to build the graph in a matter of seconds. This graph is built in a way that’s optimized for GNN learning.
To analyze churn and retention, you can include tables that are related to purchases, subscriptions, anything applicable to user history and activity, etc. Online marketplaces and ecommerce platforms can include data on the products or items sold. The more data the better!
You only need to build your graph once – once you have it, there are a near infinite number of use cases you can tackle, and you can start asking many different questions about your data.
In this example, we’ve added tables from a public dataset including anonymized customer information, which can analyze the ecommerce platform’s customers and their transactions. Link your tables based on Primary / Foreign Key relationships and you’re done!
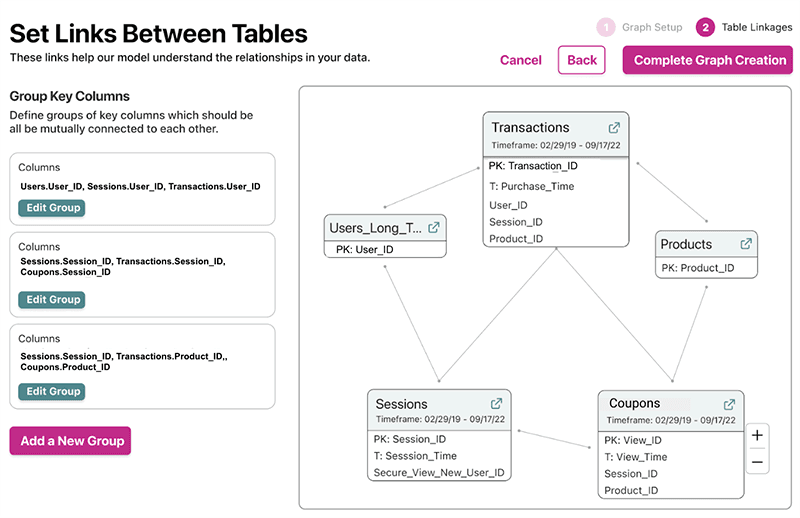
You can scale to dozens of tables, terabytes in size, with tens of billions of rows collectively. With a large graph created, Kumo will enable you to learn complex patterns and interactions from the different schemas – the more tables you connect, the greater the depth of the learning.
Now, you can reuse this same graph to build any number of predictions across a broad range of use cases. Kumo.ai will maintain and update the graph as new data comes in or as tables are updated.
From Business Problem to ML Pipeline in A Few Lines of Simple Code
With your graph built, you can now start generating predictions! Kumo offers a flexible and customizable language called the Predictive Query, which specifies the machine learning problem you’re trying to solve.
Kumo uses the query kick off an end-to-end ML pipeline (no feature engineering or pipelines needed!) where the Kumo AutoML process runs under the hood, identifying the best architecture, model, and parameters for your task and graph. You can run a near-infinite number of predictions for different types of problems in a matter of hours, each one deploying a new, unique GNN built for the specific task.
You can define what aspect of churn is relevant for your business – whether you want to predict the occurrence of high impact events or changes in aggregate activity that signal potential risk or drops in engagement.
If you define a churned user as someone who stops being active in opening sessions, you can define the following simple query to predict all users who, given they’ve been active over the past 3 months, will churn over the next 90 day period:
PREDICT NOT EXISTS(Sessions, *, 0, 90)
WHERE EXISTS(Sessions, *, -90, 0)
FOR EACH Users.ID
If you define a churned user based on transactions, you can modify the query to predict, given a user has transactions over the last 3 months, which users will stop making transactions over the next 90 day period:
PREDICT NOT EXISTS(Trans, *, 0, 90)
WHERE EXISTS(Trans, *, -90, 0)
FOR EACH Users.ID
Now, let’s assume we want to perform some form of customer outreach as a means of re-engaging them. We can re-run the query but under the condition that we send them a discount coupon within the week:
PREDICT NOT EXIST(Trans, *, 0, 90)
WHERE EXIST(Trans, *, -90, 0)
FOR EACH Users.ID
ASSUMING EXISTS(Coupons, *, 0, 7)
We can use these queries to run through any number of scenarios where we apply various outreach and retention strategies and see how the expected churn will change.
If you’d like a greater depth of customization, you could move away from the UI experience and leverage the Python SDK to craft and customize your modeling plan based on the depth of your ML experience and domain knowledge.
Below is an example config for the SDK allowing you to select model criteria.
churn_pquery = PQuery(
graph=graph,
query_str="""
PREDICT COUNT(Purchases, 0, 60) = 0
FOR EACH Users.ID WHERE COUNT(Sessions, -90, 0) > 0
ASSUMING COUNT(Coupons, 0, 7) > 0
"""
)
auto_trainer = kumo.AutoTrainer(
churn_pquery,
metrics=['auroc', 'auprc', 'precision@100', 'recall@100'],
num_trials=8,
tune_metric='auprc',
trial_early_stopping=dict(min_epochs=3),
searcher='bayesian',
num_ensembles=3,
max_epochs=100,
max_steps_per_epoch=2000,
)
auto_trainer.fit()Once you train the query, you can run the model across your entire data set. When the results are in, you can deep dive into the analysis.
Leveraging Predictions from Predictive Query
Once the predictions are ready, you can go to our evaluation dashboards to understand performance.
You can compare performance against baseline models and sanity check quality.
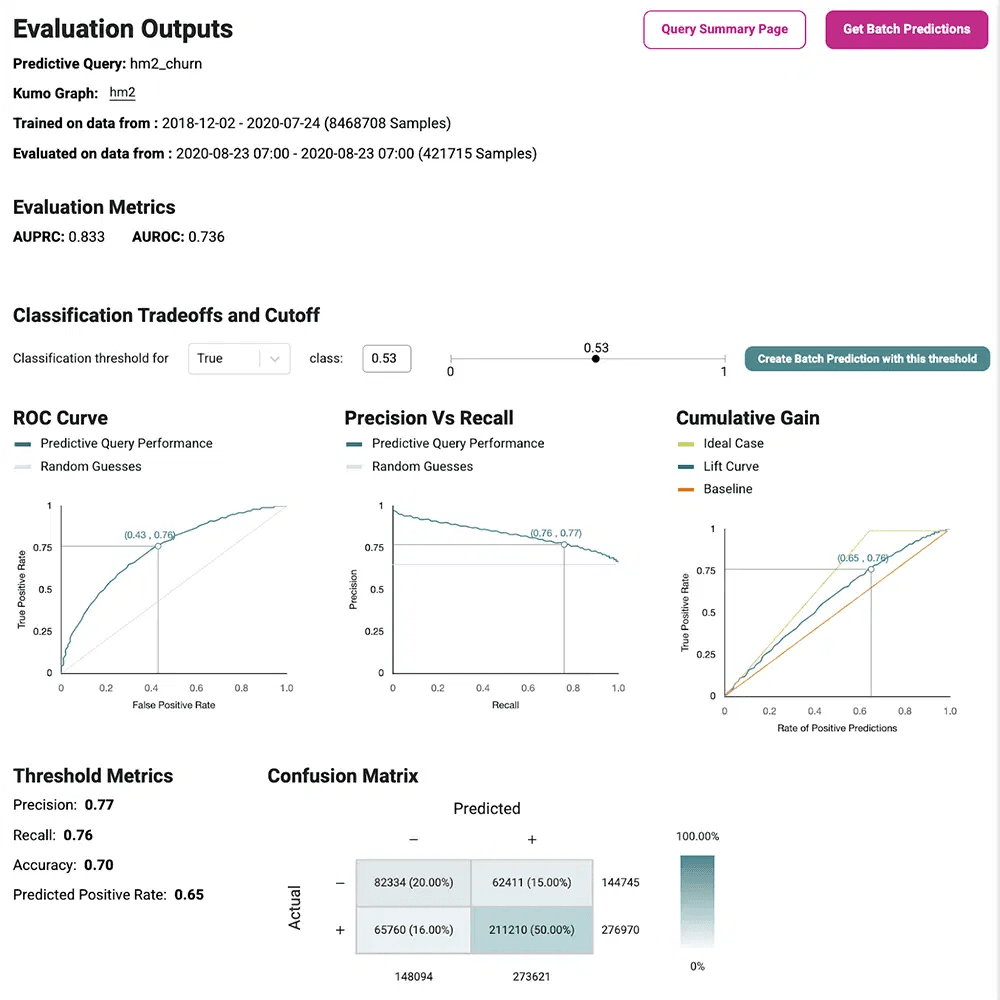
Once you identify the at-risk users, the next step is to understand why each user will churn. This can be crucial feedback for product teams to improve the customer experience. In some cases, the predicted churn reason is rooted in missing features or functionality, in others, there is some misalignment between the expectations and reality of the user behavior. Once you uncover the root cause, you can prioritize your retention strategy accordingly.
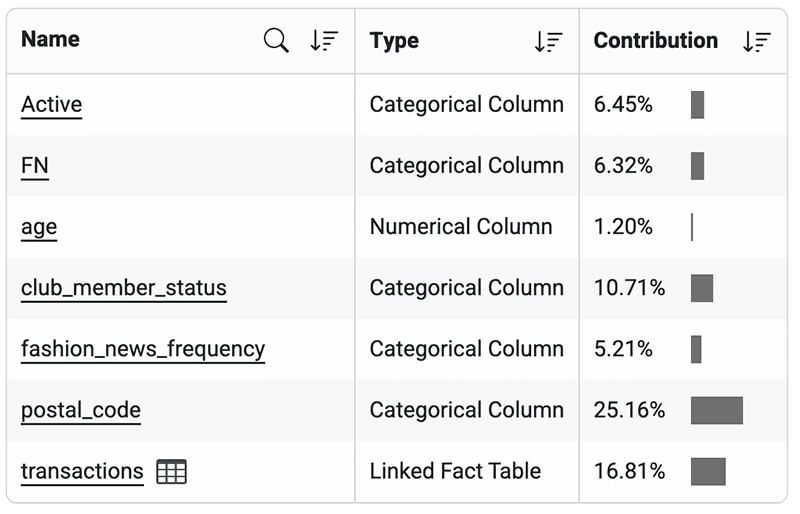
Digging deeper into column contributions will help identify features that contribute to churn and can diagnose the underlying reasons.
By looking at the feature contribution, you can identify larger trends across your user base which could be driving churn and retention. For example, we can look at features like transactions, postal code, and club membership as meaningful indicators of churn.
These drivers can inform your overall retention strategy.
So what’s next? In subsequent posts, we’ll show you how you can use Kumo to optimize your outreach strategies, determine which actions any given user segment will respond positively to, identify the high spend potential users, and more.