Graph Neural Networks (GNNs): Introduction and examples
October 21, 2022

Matthias Fey, Ivaylo Bahtchevanov

Introduction to Graphs
Most of the interesting phenomena in the world can be broken down into entities, their diverse relationships, and their dynamic interactions. This can best be described as a graph.
In short, graphs connect things. They are a mathematical abstraction that can model any entity, along with their properties, and how they relate to one another as edges.
Graphs capture both simple and complex interactions, and provide a natural representation for the data describing them. Often the most valuable and interesting data are graphs. Here are some contexts around which data can be represented naturally as a graph:
- Commerce and retail: interactions between users and products / ads, purchasing dynamics and orders
- Healthcare: biological interactions between drugs, proteins, pathways, side effects
- Finance and Insurance: financial transactions between entities
- Transportation: traffic and logistics networks
- Manufacturing: supply and value chain interactions, mechanical/fluid dynamic systems
- Social Networks: professional networks, social media platforms, communication platforms
And many more! Any data that is stored in relational databases has an inherent graph structure in the form of primary and foreign key relationships, proximity of events in time and space, and patterns across objects in tables.
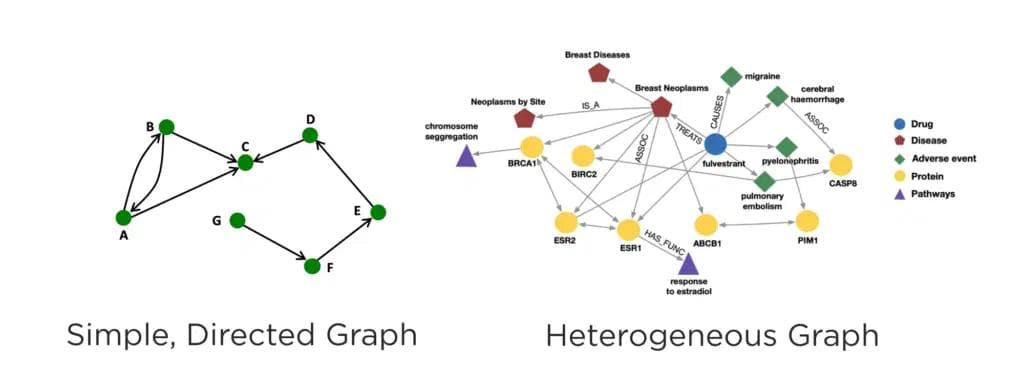
Graphs can also model both homogeneous or heterogeneous networks.
Homogeneous graphs are simple – they represent entities and relationships of a single type. For example, a collaboration network of the authors of academic papers can be represented by a single type of node – author – and a single type of edge – collaborator. A simple graph for a transaction network for anti money laundering (AML) represents banks’ customers as nodes and transactions as edges.
Heterogeneous graphs, on the other hand, contain multiple different node and edge types, which allows them to describe and capture a more complex system. For example, a drug discovery process can model drugs, proteins, pathways, and side-effects as nodes and capture the molecular interactions, activation bindings, cause-and-effect patterns between them through edges. These graphs can also describe natural graphs such as the LinkedIn Economic Graph of people, companies, schools and skills and the relationships between them.
Introduction to Graph Learning
Graph learning takes the existing graph and accomplishes one of the following machine learning tasks:
- Predict missing attributes of nodes in the graph — i.e. label an entity in financial transaction network as a fraudulent actor, or classify a user in a customer data set as highly likely to churn
- Predict missing links between nodes — i.e. determine which items to recommend to specific users, determine which two members of a social or professional network should be connected
- Predict missing nodes that may connect multiple existing nodes — identify potential side effects of drugs binding to proteins and activating pathways
- Predict characteristics or properties of subcomponents of the graph — identify a ring of fraudulent actors in a transaction network within a complex graph of transactions
- Cluster nodes in the graph based on specific properties of the nodes or link structures – identify communities of similar individuals that would purchase the same set of items
Graphs lead to better ML models. Traditional ML and DL algorithms assume a fixed sequence for an input (represented by flat vectors for images, tables, text), which is frequently a bad assumption when dealing with real world richly-networked data. Graph learning, on the other hand, takes the graph as is and learns from its inherent structure. Specifically, since nodes in a graph are interconnected, predictions made on graphs can leverage the surrounding graph context, learning across the entire network rather than treating each node or prediction as independent. Predictions on connected nodes and edges all inform each other, maximizing the signal from the entire network.
Graph Neural Networks and their Benefits
The most effective and recent advancements in the field of graph learning are Graph Neural Networks. GNNs are an emerging family of deep learning algorithms that bring together all the advantages from traditional deep learning to graphs. GNNs can learn patterns and relations on a giant scale, combining features from neighboring nodes, and train predictive models across the entire network.
Here are some of the many advantages of GNNs over traditional approaches:
GNNs adapt to the shape of the data
Other methods assume a fixed input (matrix or sequence) while GNNs capture patterns across all nodes locally. GNNs learn the rich representations directly and optimally from the raw data without any usually suboptimal and time-intensive manual feature engineering.
GNNs provide the most flexible architecture
GNNs glue together other Neural Network architectures and integrate multimodal data.
Architectures from CNNs, Transformers, and other best-in-class architectures for specific problems are naturally incorporated. GNNs are extremely general – they can subsume the above methods as special cases but are a fundamentally generic approach to any problem.
Common Applications for GNNs
Graph neural networks lead to fundamentally improved model quality and accuracy compared to traditional deep learning approaches in a number of applications – including financial transaction analysis, recommender systems, natural language processing, computer vision, biomedicine, simulations, and more.
Financial Networks
Graphs describe and capture dynamic financial networks by modeling financial entities as nodes and their interconnections or interactions as edges. Modeling a transaction network as a graph enables you to build effective representations of the finance domain to solve problems across a number of related areas.
Graphs are particularly useful for detecting fraudulent or risky activity through anomaly detection, or identify broader financial crime because, in these cases, there are typically very few examples of risk or crime in your historic data to learn from and often labels for many nodes that are missing. The ability to use the surrounding context of the graph and propagate labels across neighboring nodes compensates for the lack of negative samples. In fraud and abuse you can detect fraudulent transactions with a node or edge level classifier.
Graphs can also be useful in identifying anti-money laundering by isolating entire subgraph networks that exhibit specific characteristics. Suspicious transactions can be flagged using anomaly detection, and subgraph-level classification can detect rings of connected fraudulent actors, money laundering rings, or terrorist funding networks.
Finally, graphs can effectively model purchasing behavior and forecast future behavior. Predicting future transactions and transaction volume can be simplified to link and node prediction, respectively, on a graph. For instance, the Central Bank of a European country was able to process dynamic graphs of tens of millions of transactions and improve their accuracy from 43 to 76 percent using graph ML, results remained robust to changes in transaction patterns.
Abuse Detection
Another common use case for graph ML is detecting harmful, abusive, or malicious behavior across any network where interactions between entities occur – ie social networks, professional networks, marketplaces, or transaction networks. For example, AirBnB uses GNNs to understand host behavior and ensure trust and safety of listings across all users on the platform. GNNs are extremely useful when a new host joins the platform, and there is very little to no historical data about the host for traditional ML models to learn from. Graph learning makes use of the host’s connections to construct a detailed understanding of the users – the semantic information provides strong baseline knowledge until there is more factual information about the user.
Recommender Systems
Naturally, graphs emerge in the context of user and customer interactions with products in ecommerce platforms or content consumption / media platforms, and as a result, many companies employ GNNs for product and content recommendations. A common use case is to model interactions within the graph of users and items, learn node embeddings, and retrieve similar items for given users.
Community detection through subgraph level classification can be used to recommend items to communities. Community detection can also group similar items into categories or users into types of buyers. A sub-graph level task can then enable the prediction of long-term value (LTV) or other buying behavior for these categories.
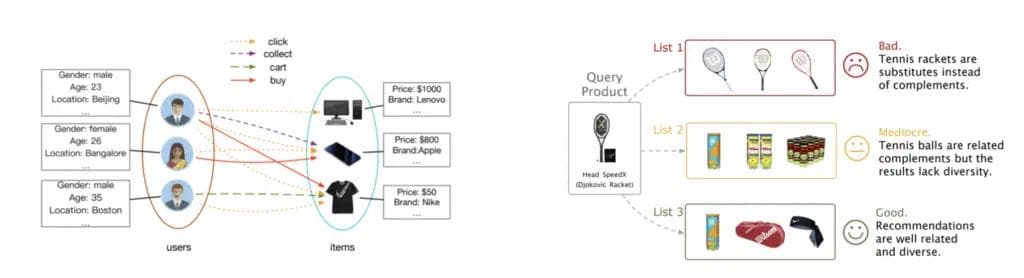
Leading ecommerce platforms like Amazon and Alibaba use GNNs for their product recommendations; Uber Eats leverages GNNs to encode information about users, restaurants, and menu items to generate personalized recommendations of local meal options to users based on specific taste and preferences; and Spotify uses GNNs to recommend podcasts and playlists to users in their homepage.
All of these recommender systems benefit greatly from GNNs when new users or new items are added to the platform, and the models can infer latent features based on limited historical data.
Biomedicine
It’s common for researchers in academia, medicine and industry to collaborate on the construction of large biomedical knowledge graphs that model biological systems from the molecular level up. Entities in these knowledge graphs include nucleic acids, genes, proteins, enzymes, reactions, metabolic pathways, organs, organ systems, diseases, medications, side effects, individuals, case studies, terminology, insurance codes and clinical guidelines.
While traditional ML/DL approaches can model these knowledge graphs, they often require domain experts to be actively involved in encoding their subject matter expertise into features and model capabilities.
GNNs can infer the underlying structure of the knowledge graph and can reduce the manual effort involved from subject matter experts in building the right features. For example, in molecular biology, we rely heavily on domain experts generating molecular “fingerprints” to properly train the model, while GNNs can learn these fingerprints from the data structure and can reduce the dependency on manual fingerprint creation.
GNNs can help build models that work in terms of complex underlying mechanisms and interactions between pairs of nodes among diseases, drugs, pathways, proteins, side effects; links can be any interactions between any of those nodes.
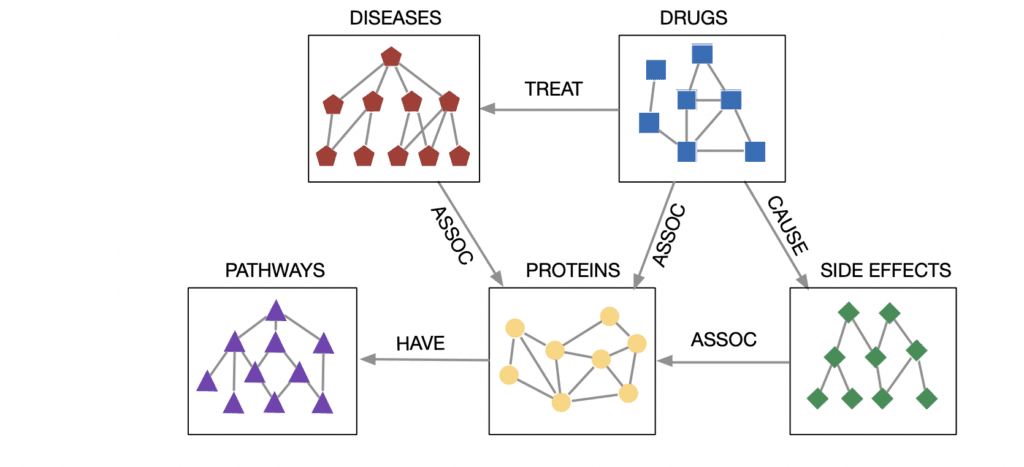
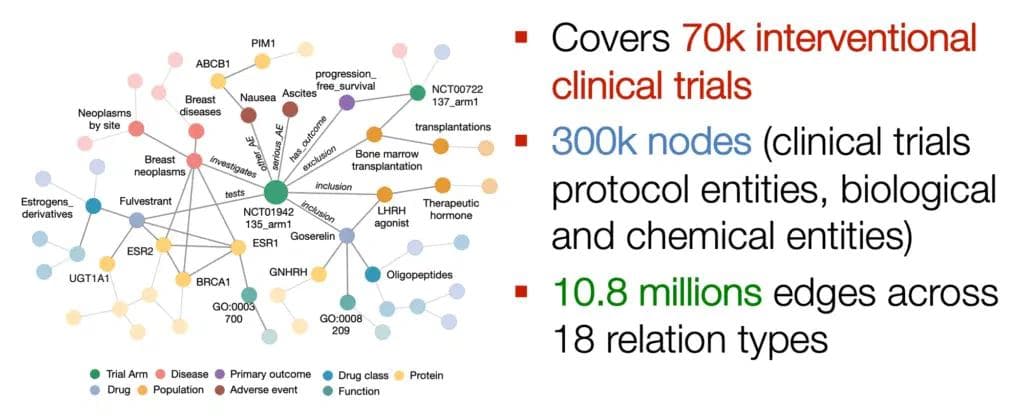
Node or graph level tasks can predict drugs that target specific proteins that prevent specific diseases. Link prediction can discover new drug interactions, research avenues for cures. Link prediction can also be used to model all possible side effects of medications via link prediction using drug-protein and protein-protein interactions. GNNs in biomedicine can also power end-to-end solutions to sophisticated business problems such as clinical trial prediction.
Natural Language Processing
Trustworthy NLP systems require predictions that are grounded in real world dynamics. Traditional language models encode common-sense knowledge implicitly during pre-training, but this representation is not robust or reliable.
Graph representations can bring language and knowledge together in a shared semantic space – GNNs build knowledge graphs that can explicitly teach common-sense relationships, which allow language models to generalize relationships to a broader set of implicitly encoded concepts. For example, combining language models with a knowledge graph provides enhanced reasoning and deeper context understanding for Question-Answering applications.
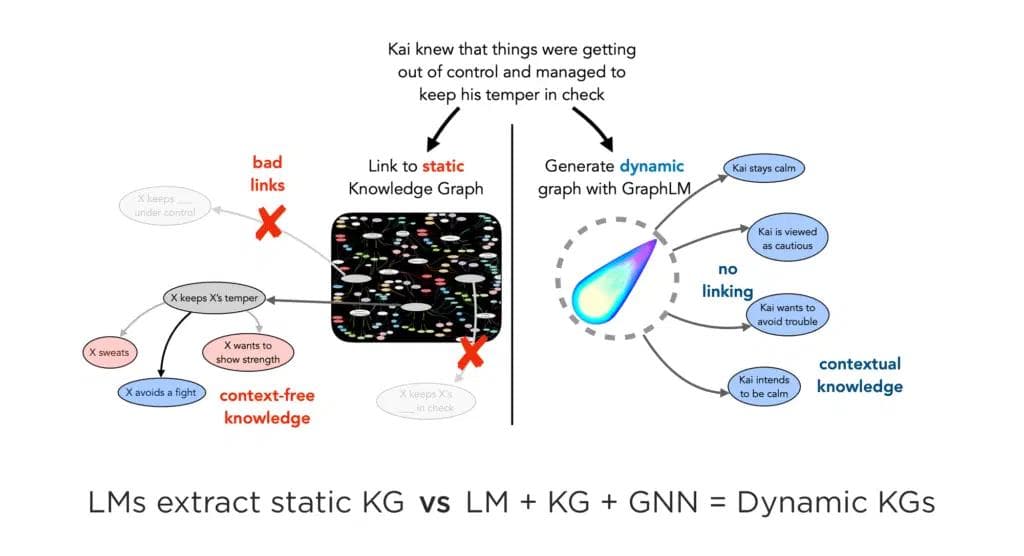
Training on the knowledge graph provides the models with higher levels of domain knowledge, reasoning capabilities, and common sense.
Computer Vision and Graphics
While most graph applications use graphs without physical positions, 2D and 3D objects in physical space fit well into a GNN representation for solving machine learning tasks associated with these datasets. GNNs are effective at extracting representations from object hierarchies, point clouds and meshes as well as complex geometric structures.
Entities or nodes in a graph for computer vision and graphics can be anything from 2D or 3D points to scene objects or keypoints (key object parts). Edges capture the Cartesian / polar relationship and hierarchical relationships in a mesh. Tasks for GNNs in computer vision include smoothing 3D meshes, simulating physical interactions between objects and extracting relationships between objects in a scene.
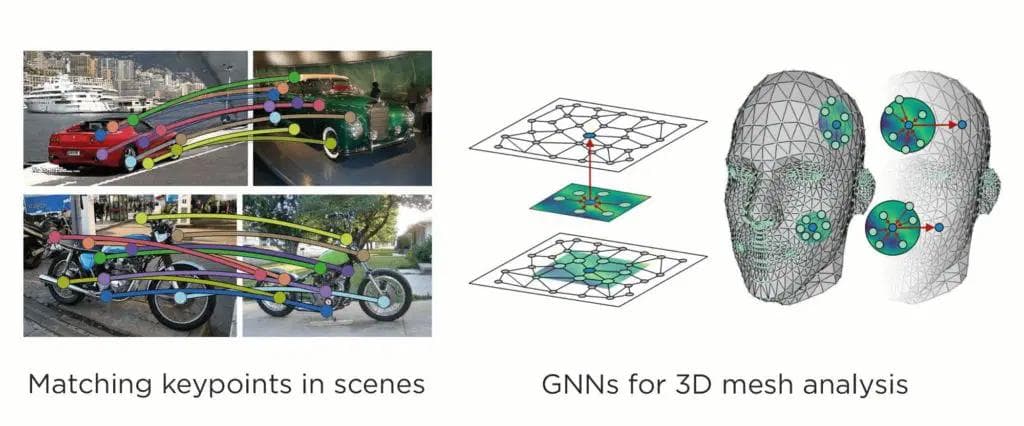
Simulations
Complex systems can be modeled by interactions between their particles such as molecular dynamics, fluid dynamics or astrophysics simulation for cosmology. GNNs can model particle systems to simulate the interactions between particles in a much more efficient manner than can a raw simulation. These models can predict complex behavior in production lines, power grids, robotics, or weather patterns.
Simulations can also be useful for modeling an entire supply chain, a highly interconnected and dynamic network with many moving pieces, making GNNs particularly effective at forecasting predictions and supply chain optimizations.
What Tools Can I Take Advantage of Today?
While GNNs aim to generalize concepts of deep learning on graph data, this generalization provides new challenges in implementing them from scratch, such as:
- Graphs have an arbitrary size and complex topological structure, which is very different from the traditional underlying structure of images and text
- There is no fixed node ordering or reference point, which requires any graph model to be independent of a given ordering
- Graphs are dynamic, meaning their underlying structure can change over time
- Node and edge features can be multimodal, requiring a dedicated approach for combining those different representations into unified embeddings
These challenges result in the need for specific solutions and toolboxes for implementing GNNs. One such solution is PyTorch Geometric – i.e. PyG.
If you are a data scientist, machine learning engineer, or researcher, PyG (PyTorch Geometric) greatly simplifies working with both simple and complex graphs, making it easy to build and manage GNNs with the same design principles of PyTorch.
PyG is one of the most popular and commonly-used graph learning library across industry and research – with over 80 contributed GNN architectures and 200+ benchmark datasets, PyG provides a simple interface to stack different lego blocks into a new state-of-the-art model for any use case.
PyG has a strong partner ecosystem powering its operations. The PyG-Nvidia collaboration brings together GPU-accelerated execution, and the Py-Intel collaboration accelerates inference and sampling on CPUs. Leading enterprises have built core predictive operations on top of PyG – Spotify’s homepage recommendations, Airbus’s anomaly detection, and AstraZeneca’s drug discovery are all powered by PyG.
PyG has a very strong community of active contributors and developers. Having over 100k monthly downloads and over 300 external contributors (in aggregate providing around 6k contributions/month), PyG provides a broad algorithmic toolbox and supports the long-tail of use cases and data formats.
Slack is the best starting point for getting up and running quickly.
When it comes to leveraging the same capabilities within enterprise applications, there’s a big divergence in opportunities and challenges between organizations – more mature organizations often have extensive infrastructure and headcount to throw at any AI problem, while smaller companies face significant headwinds to do the same. Building a pipeline for even one prediction problem is complex, expensive and time-consuming. You can find many start-ups offering point solutions, but regardless of whether you decide to build or buy, you still end up stitching together a pipeline connecting and integrating all of these tools – and contributing multiple engineers per model.
Kumo makes it possible for users to immediately tackle generating dozens of prediction problems by setting up a single data connection and pointing to a source of data – Kumo will create the graph and handle the rest.
If you examine the role of a data scientist, they are effectively capturing a network structure of entities and relationships in their warehouse. The idea behind Kumo is that if a user (typically an analyst) can point to what the key entities and tables are for any given business problem, Kumo can transform it into a network architecture and apply GNN-based AutoML.
Kumo amplifies the data scientist, allowing them to perform many prediction problems on the same data warehouse in a matter of minutes. The analyst gets the lowest time to first model from automatic graph and training dataset creation, smart temporal sampling with zero leakage, instant productionisation, high quality and scalable models out-of-the-box, and a simple interface to make any prediction for any business problem.
All a user needs to do is connect their data warehouse or raw data storage, and Kumo will assemble the graph under the hood. Once the graph is created, it becomes quick and easy to make any number of predictions on the data using a simple SQL-like interface – without any additional effort in data processing or retraining for subsequent predictions.
The traditional process of target label engineering, feature engineering, architecture and hyper-parameter search, and ML Ops are all abstracted away, making it easy for an analyst to perform the same predictions that would typically involve many engineers and many cycles of data engineering, training, and model tuning.
Finally, Kumo also handles the enterprise and governance capabilities with a control plane using standard tools (authentication and permissions, secure data plane, managed training infrastructure, compute through VMs backed by K8s, monitoring/logging using Grafana, etc.) so users can focus on doing their most important and productive work and on answering important business questions.