Enabling Kumo’s predictive AI natively in Snowflake
June 11, 2024
Kumo team
Kumo is a cutting-edge predictive AI solution. Kumo simplifies the end-to-end process to build AI models and accelerates time-to-value. Central to this transformative approach is an AI purpose-built for finding hidden patterns in relational data using large language models (LLMs) and graph neural networks (GNNs). Predictive tasks are specified using a declarative SQL-like predictive query language. Kumo harnesses the interconnected relationships in relational data to build a predictive model that makes highly accurate predictions about behaviors, segments, lifetime value, and more to improve revenue impacting KPIs. All this happens without any manual feature engineering or training data set creation. With Kumo, data scientists build more accurate predictive models in a fraction of time.
Kumo is now available in Private Preview as a Snowflake Native App. In this blog post, we describe how we integrated Kumo with the Snowflake ecosystem to allow users to build powerful predictive AI models using their private, relational data in Snowflake. Kumo uses Snowflake’s managed container offering, Snowpark Container Services (SPCS), and runs inside the user’s Snowflake Data Cloud without their data ever leaving Snowflake. On-demand GPU compute instances available in SPCS are used to train Kumo’s predictive models. Kumo uses Snowpark APIs to process relational data at scale (100s of GBs and billions of rows of data), represent it as a relational entity graph, and execute the predictive query to train Kumo’s AI model. Kumo also integrates with Snowflake’s access control mechanisms and provides users with control over all privileges Kumo is granted to operate in their Snowflake Data Cloud.
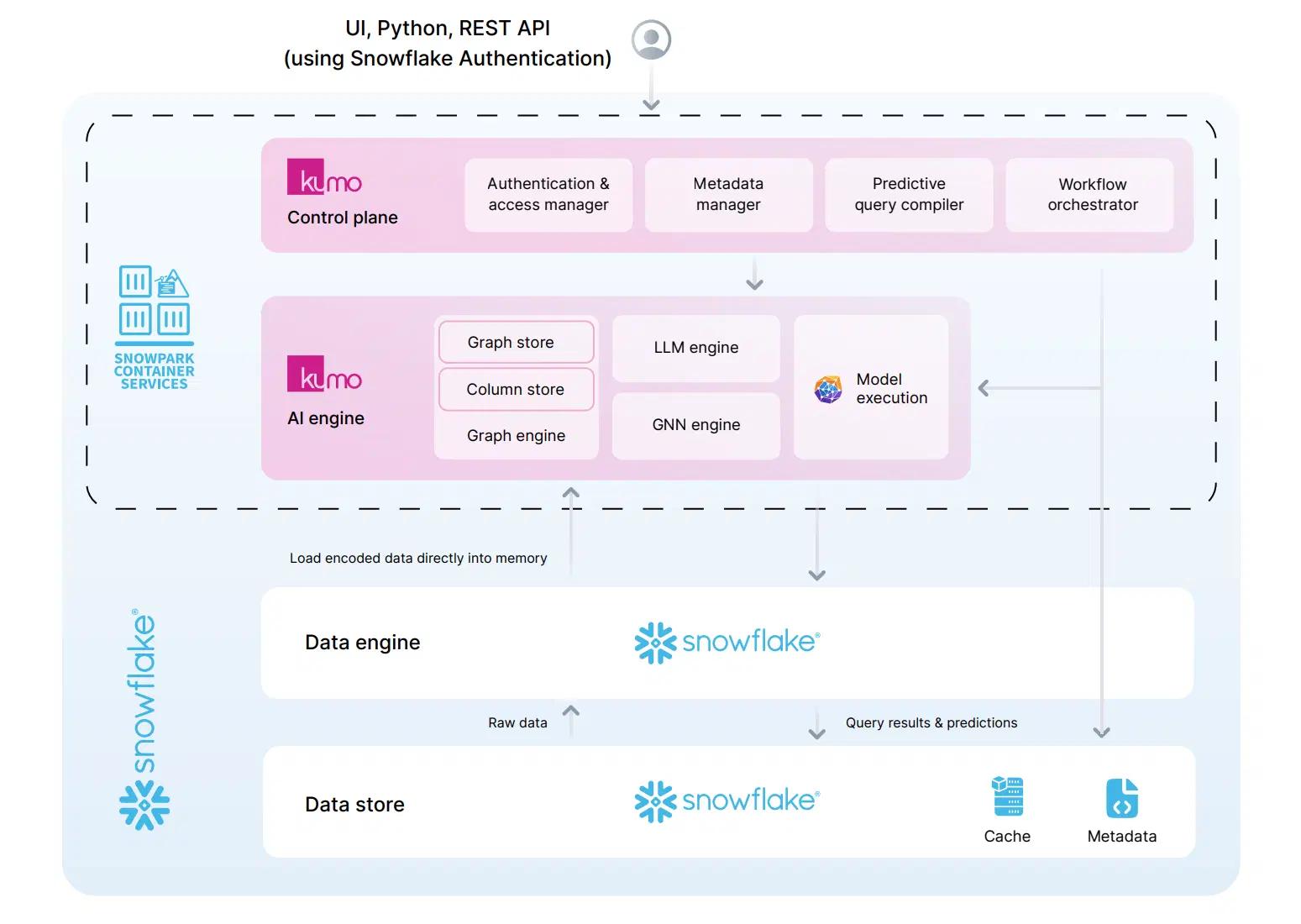
Kumo leverages multiple containers to enable users to connect to and process their Snowflake data, and build predictive AI models. It consists of the following (logical) components (as shown in the figure above):
- The Control Plane which includes (a) an authentication and access control manager that integrates with client’s Snowflake access controls, (b) a metadata manager that manages all metadata in Kumo, (c) a compiler that both translates predictive queries to a predictive model training plan, and (d) a workflow orchestrator to coordinate various activities across Kumo; we rely on Temporal Cloud for orchestration and run multiple temporal workers to perform different tasks.
- The Kumo AI engine processes predictive queries and builds predictive models. It leverages Snowpark APIs as the Data engine to process input relational data in a client’s Snowflake Data Cloud based on the input predictive query. The result is a relational entity graph and training data that is used subsequently to build Kumo’s (GNN-LLM) AI model. The Kumo AI engine consists of:
- A Graph engine which loads relational entity graphs and (node) attributes generated by the Data engine, into the Graph and Column store respectively. Its primary role is to serve subgraph sampling requests and node attributes for the GNN training and predictions. It leverages a Graph Store to store all entities in the data warehouse (rows) and a Column Store to store all attributes about such entities (columns).
- The GNN engine is responsible for GNN computations and predictions on the relational data. The LLM engine is responsible for working with pre-trained LLMs, which brings general-world knowledge to the user’s relational data via Kumo’s GNN-LLM model. Kumo works with both open-source and commercial LLMs.
- Model execution combines the GNN and the LLM parts of the architecture and uses the available GPU compute in Snowflake to train the GNN-LLM model for a given predictive query on user’s data.
All the above components are implemented using multiple Docker containers (Web server, REST container, etc.), each running as a Snowpark container. Kumo is integrated with SPCS using the following:
- Our existing tooling and images work out of the box with SPCS with minor modifications as Snowflake image repositories are OCIv2 compliant.
- Compute: Kumo is built as a long running service in SPCS — all the containers required are defined and launched using a service specification file. For Private Preview, all containers run on a single, on-demand GPU instance — the GPU is utilized to run training and predictions in a performant manner.
- Storage: All metadata and intermediate data are materialized to temporary tables and stage-mounted local volumes in the user’s account. Stage mounted local volumes provide shared storage abstraction between different containers in Kumo and are optimized for large data. Block storage volumes are used for performing highly parallel I/O where stages can be slow.
- Network: Kumo provides a web-based UI for easy interaction with the product and relies on external services like Temporal Cloud for workflow orchestration. We rely on enabling Snowflake’s network ingress and egress rules (restricted to a minimal required set) to enable such connectivity.
Data processing at scale using Snowpark APIs
Kumo’s AI engine is capable of handling tens of tables with 100s of GBs of data or more. Such tables cannot be loaded entirely into memory on a single machine. Hence, Kumo uses a Data engine to perform all data operations at scale. These operations include loading raw tables from the user’s Snowflake Data Cloud, converting data to match Kumo’s internal formats, calculating statistics on columns to inform the model parameters, and creating the internal representations of tables to be fed into the GPU for training and prediction.
Kumo uses Snowpark Python APIs as its Data engine. Snowpark provides a DataFrame class and SQL operation functions. These APIs allow Kumo to perform complex data operations and use Snowflake warehouses to scale as needed. The computations for Snowpark operations performed on these DataFrames run in the Snowflake warehouse where the source data is located. This consolidates the storage and computation together, ensuring everything stays within the user’s Snowflake account. Intermediate representations of the data are persisted from DataFrames to Snowflake stages in the same Snowflake warehouse, and final predictions are written as Snowflake tables.
Distributing Kumo as a Snowflake Native App
While the Snowpark Container Services framework provides the right abstractions to run Kumo inside the Snowflake ecosystem, the Snowflake Native App framework enables the distribution of Kumo to thousands of Snowflake users seamlessly, without exposure to implementation details of SPCS, e.g., managing docker images, multiple containers etc. Snowflake customers can search for and request access to Kumo from the Snowflake Marketplace.
Kumo is built as a Snowflake Native App using the following:
- A manifest file to define the properties of Kumo as a native app including the images to use when shared with a customer and the required privileges for the app.
- A setup script to (a) define the abstractions needed to operate Kumo (e.g. start the application, get end points, debugging information etc.), (b) define Snowflake objects (e.g. schemas, tables, stages etc.) that are needed to start Kumo and finally, (c) create the necessary roles and grant privileges required to users to access the objects defined in (a) and (b).
- A service specification file which is equivalent to the one used for SPCS integration with minor changes (e.g. modifying absolute image repository URLs to relative URLs).
The above artifacts are used to build an application package. The package is then shared with Kumo customers as a listing on the Snowflake Marketplace. Support for versioning in the Native app framework is used to specify a version and patch number for each application package to uniquely identify releases and mark stable releases as release directives.
Integrating Kumo’s GNN with Cortex
Kumo’s predictive AI integrates GNNs with LLMs. Kumo’s approach combines the strengths of both technologies, enhancing their individual predictive capability. GNNs excel at capturing relationships and patterns in relational tables, by leveraging the connectivity information. Meanwhile, LLMs are adept at reasoning and understanding real-world entities and are filled with common-sense knowledge, making them powerful tools for tasks involving real-world entities. By integrating GNNs with LLMs, Kumo’s predictive AI system effectively utilizes both structured and unstructured data, improving accuracy and contextual understanding. This synergy enables more sophisticated predictions and insights, leveraging the deep relational data processing of GNNs and the nuanced language comprehension and reasoning of LLMs.
Kumo leverages Cortex LLM and integrates it with GNNs in its Snowflake Native App. Using Snowflake Cortex LLM, Kumo’s predictive performance is further improved, particularly on “cold start” tasks that require common-sense general world knowledge.
Security
User authentication: Kumo provides a web-based UI along with REST endpoints that are only accessible using Snowflake Oauth integration and are therefore protected by the user’s Snowflake login. Only users who are explicitly granted the role or privilege to use Kumo by their Snowflake admin can access it within the Snowflake account. Further, Kumo runs behind a Snowflake proxy service which provides an additional layer of security.
Access control: One of the key benefits of Kumo’s Snowflake Native App is the familiar security and governance capabilities it provides. Kumo runs entirely within the user’s Snowflake account and cannot access any Snowflake objects (databases, schemas, tables, views etc.) by default. Snowflake’s access control model is followed and users need to explicitly grant each privilege to the Kumo to enable access to any Snowflake object in their account.
Best practices for developing Native Apps with SPCS
Our team is experienced with building and managing the Kumo SaaS platform on top of AWS. As we integrated natively with SPCS, we discovered the following differences and want to share the learnings with other SPCS and Snowflake Native Apps developers.
Development and testing: Containers running in SPCS do not provide the typical exec command to enable a shell into the container. This provides a powerful tool to debug and test containerized applications. The default way to observe the behavior of a service running in SPCS is the container logs. Iterating through the development cycle using logs can be a sub-optimal process. To enable interactive debugging during development (e.g. attaching a debugger), a web-based terminal is spun up in the containers and is configured to be accessible through Snowflake authentication.
I/O capabilities: Local volume-mounted stages provide a NFS-like local filesystem abstraction that’s shared across all containers using the same stage. While this provides a great abstraction for managing shared state, such mounted stages are not optimized for large read/write throughput or concurrent I/O. For portions of the Kumo application that require highly concurrent reads/writes, we worked around these limitations using the FileOperation API to put/get files to/from stages and relied on block storage volumes for concurrent I/O.
Network constraints: All ingress and egress connections to an application running in SPCS go through a Snowflake-managed proxy. A short timeout (15 seconds during our development of Kumo) is enforced for ingress requests, requiring any response to be returned within the specified time period. Further, network maintenance events can result in long lived connections to external services being dropped. This requires techniques to detect such events (e.g. timeouts) and recreation of the connections as needed.
Observability: Container logs written to the event table configured for an account provide the primary way to observe the behavior of the application when running in a user’s account. As one is unable to access user environments, it is imperative to ensure logs are detailed enough to provide sufficient understanding of what led to an error. During development, we also enabled pushing logs to Grafana cloud which is the preferred solution for Kumo’s SaaS offering.
Snowpark APIs: Kumo and Snowpark handle data types differently. For example, Kumo automatically parses and converts timestamps presented in string or numeric formats. While Kumo timestamps default to UTC, Snowflake Timestamp types may be provided in a variety of formats and timezones. Data processing using Snowpark APIs, as with any data engine, requires appropriate handling of data types and being fully cognizant of the semantics of all the APIs being used. It’s important to define the differences between the application and the data engine and ensure all possible combinations are tested.
SPCS and Native Apps with SPCS are new and evolving services in Snowflake. We have been closely partnering with various teams at Snowflake who are actively working on addressing the above constraints (e.g. Snowflake metrics can now be published to Grafana Cloud).
How to get started
To try out Kumo during the Private Preview as a Snowflake Native app, you can request access on the Snowflake marketplace.
Acknowledgements
We would like to thank everyone at Snowflake for their close partnership in developing our Snowflake Native App. We are especially appreciative of Chris Cardillo, Eduardo Laureano, Mike Klaczynski, Muzz Imam, and Su Dogra at Snowflake for their help.