





Kumo is an AI for quickly building highly accurate predictive models using the entirety of the data warehouse: multiple tables, both structured and unstructured. Kumo uses embedding tuning to uniquely combine pre-trained large language models (LLMs) with graph transformer architectures to improve accuracy by double-digits in days. Kumo’s models can be refined by domain experts for maximum performance improvements.
Recently the data science and engineering teams at Kumo AI ran several experiments with a product recommendation task to see how different LLMs improve recommendation accuracy. The task is to predict the products a customer is going to buy in the next 7 days.
For the AI model to produce accurate recommendations it needs a detailed understanding of product properties as well as customer preferences. Products as well as customers are often associated with unstructured textual information like product names, product descriptions, customer reviews, and more. It is critical for the recommender system to include text understanding capability because so much information is stored in unstructured text.
At the same time, graph information is highly valuable in recommender systems because it captures complex relationships between customers, products, and their interactions. Graphs represent the relationships between customers and products as edges, allowing the system to consider not just direct interactions (like purchases or ratings) but also indirect connections (e.g., customers who like similar products or products that are liked by similar customers).
Furthermore, in some recommender systems, social relationships between customers (e.g., friendships) are also represented as graphs, which can enhance recommendations by incorporating preferences from a customer’s social circle. In graph-based systems, higher-order connections (i.e., multi-hop relationships) can be leveraged.
For instance, if Customer A likes a product that Customer B liked, and Customer C is similar to Customer B, the system might recommend that product to Customer C as well. Overall, graph-based models provide a nuanced understanding of customers’ preferences by considering both direct and indirect interactions. This enables highly personalized recommendations, taking into account more contextual information about the customer and their network.
The Kumo team experimented with four variations of how textual information can be processed on the same recommendation task:
- LLM-only: OpenAI text-embedding-3-large alone
- Kumo-only: Kumo alone (uses GloVe for embeddings)
- Kumo+HuggingFace: Kumo + Hugging Face intfloat/e5-base-v2 LLM
- Kumo+OpenAI: Kumo + OpenAI text-embedding-3-large LLM
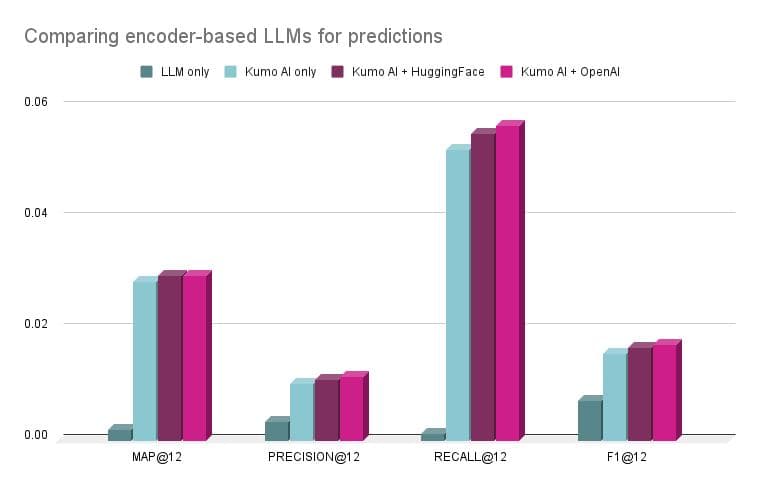
Surprisingly, results show that Large Language Models by themselves work very poorly at personalized recommendations. Even though LLM is used to produce an embedding based on all the product information and characteristics, such models fail to capture nuanced customer behavior in its embeddings. A graph-based approach, like Kumo, captures customer behavior much better and improves the recommendation accuracy over the LLM by 15x (MAP@12). Combining Kumo with LLM-based encoding of textual fields achieves the highest performance, ranging from 4% to ~11% improvements over the graph-only approach. Interestingly, we find that Kumo+OpenAI LLM slightly but consistently beats the Kumo+HuggingFace LLM.
What are encoder-based LLMs?
Encoder-based LLMs are a type of language model that utilize encoder architecture to extract relevant textual information from text data and generate continuous vector representations, known as embeddings. From BERT to more recent sentence transformers, encoder-based large language models have progressively achieved state-of-the-art vector representations for textual data.
These models efficiently encapsulate not only semantic meaning but also context-sensitive information within the embeddings. The embeddings produced can be directly applied to various downstream tasks, including semantic search, sentiment analysis, and recommendation, without the need to finetune the underlying language model.
These textual embeddings can then be directly used to identify related products. More importantly, Kumo can automatically combine textual embeddings produced by these encoder-based LLMs with the graph-based information to produce even more accurate recommendations.
How does Kumo work with embeddings generated by encoder-based LLMs?
In this experiment, Kumo brings together two technologies: graph learning via graph transformers and natural language understanding via encoder-based LLMs.
Kumo supports a Sequence data type that can directly utilize encoder-based LLMs text vector representations (i.e. embeddings), as feature inputs for Kumo’s graph neural network (graph transformer). The Sequence data type allows Kumo’s graph transformer to coalesce text embeddings with various other data types, such as numerical, timestamp, and multi-categorical, across different tables. Encapsulating both semantic meaning and context-sensitive textual information through text embeddings enhances Kumo’s ability to make accurate predictions from structured as well as unstructured relational data.
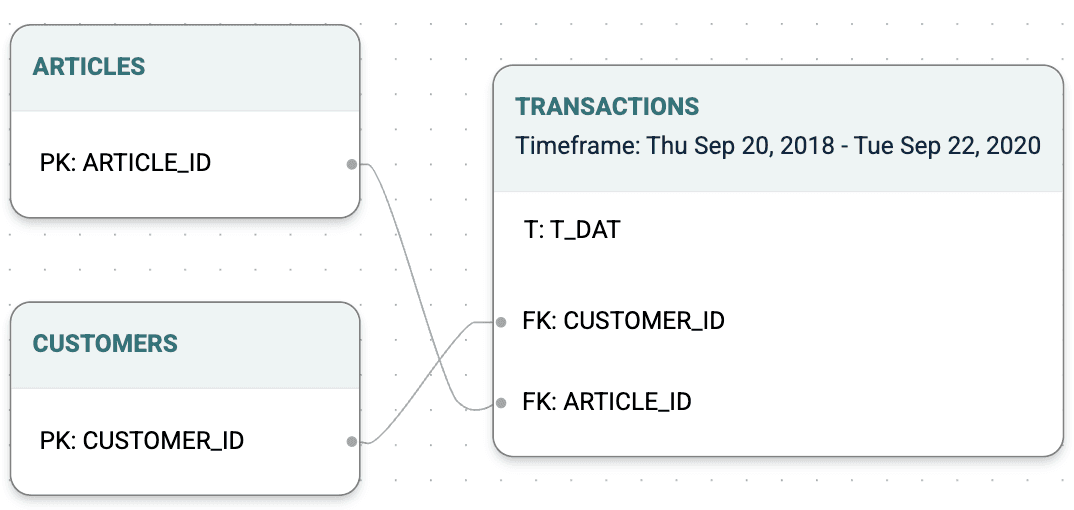
H&M Dataset and Kumo’s graph for personalized recommendations experiments:
H&M Personalized Fashion Recommendations is a dataset for product (articles) recommendation for customers based on data from previous transactions provided publicly by H&M for data science experiments. The dataset contains three tables: customers, transactions and articles which were linked in a Kumo graph using primary (PK) and foreign key (FK) relationships.
The goal is to predict/recommend the top 12 articles that each customer is likely to buy in the next 7 days.
H&M tables linked in a Kumo graph:
Sample of text columns in the articles table:
Samples of categorical columns in the articles table:

Experiments
LLM-only: OpenAI text-embedding-3-large
Our LLM-only recommender system relies solely on OpenAI LLM embeddings. To generate personalized recommendations for each customer, customer embeddings and embeddings of articles must be computed first.
We compute product embeddings by concatenating all the product information into a single long sentence (For example: “Product name: <name>. Product description: <description>. Color: <color>. Material: <material>, …”). We then compute the customer embedding as the average of the embeddings of products that the customer has purchased in the past.
To produce recommendations we take an embedding of a given customer and identify 12 products whose embeddings have the highest cosine similarities with the embedding of the customer.
Kumo-only (Kumo with GloVe for embeddings)
Kumo uses the Customer-Transaction-Articles schema to build a heterogeneous temporal graph where each customer is connected to her transactions and each transaction is connected to the corresponding product. Because product nodes have textual information attached to them, Kumo uses GloVe to encode textual information—Kumo averages word-level GloVe embeddings of all the words in a given column.
Kumo then uses the following predictive query to create the prediction for each customer:
1PREDICT LIST_DISTINCT(TRANSACTIONS.ARTICLE_ID, 0, 7, days) RANK TOP 12
2FOR EACH CUSTOMERS.CUSTOMER_IDKumo automatically learns useful signals from Customers, Transactions, and Articles tables to make recommendations. In addition to the structured data in the tables, there is useful information included in the unstructured text and categorical columns, such as shape (round), material (cotton), and type (trainer).
Kumo + HuggingFace (intfloat/e5-base-v2 LLM)
In the next experiment, the team then combined Kumo’s predictive approach with the intfloat/e5-base-v2 model, an open source encoder-based large language model, to pre-embed text and string categorical columns in the articles table. In general, all semantically meaningful columns, such as the text columns prod_name and detail_desc are concatenated into rows of strings. The text encoder encodes concatenated strings into text embeddings. The same predictive query is then trained with the LLM as the text embedding encoder in the articles table.
Kumo + OpenAI (text-embedding-3-large LLM)
Finally, the team combined Kumo with OpenAI text-embedding-3-large with 1024 output dimensions to represent each article by textifying semantically meaningful columns. The same predictive query was trained with OpenAI’s LLM as an encoder of the textual columns in the articles table.
Kumo’s integration with different LLMs.
Results of encoder-based LLM experiments for personalized recommendations
| MAP@12 | PRECISION@12 | RECALL@12 | F1@12 | |
|---|---|---|---|---|
| LLM-only: OpenAI text-embedding-3-large | 0.00190 (-93.33%) | 0.00329 (-67.84%) | 0.00119 (-97.73%) | 0.0071 (-54.60%) |
| Kumo-only: uses GloVe for text embeddings | 0.02856 | 0.01023 | 0.05234 | 0.01564 |
| Kumo+HuggingFace: uses intfloat/e5-base-v2 for text embeddings | 0.0297 (+4.00%) | 0.01099 (+7.43%) | 0.05531 (+5.67%) | 0.01673 (+6.97%) |
| Kumo+OpenAI: uses text-embedding-3-large for text embeddings | 0.02976 (+4.20%) | 0.01139 (11.34%) | 0.0567 (+8.33%) | 0.0173 (+10.61%) |
Conclusion
From these experiments we can draw several important conclusions:
- Large Language Models alone perform very poorly in product recommendation and personalization tasks. In fact, depending on the metric LLMs by themselves perform between 2x (F1@12) to 40x worse (RECALL@12) than graph-based approaches.
- Graph-based approaches, like Kumo, by themselves give excellent results, heavily improving over the LLM baseline (15x in MAP@12).
- Better text embeddings provided by modern LLMs further improve Kumo’s performance by 4% to 11%, depending on the metric.
Overall, the performance of Kumo’s GNN models can be significantly improved by combining its out of the box predictions with encoder-based large language model text embeddings. Keeping up-to-date with advancements in LLMs will help Kumo customers create the most accurate predictions possible.
Metrics
Four different metrics were used to evaluate performance:
- MAP@12: Mean of the average precision scores, where average precision is the average of precision values calculated at the ranks where relevant items are found, up to the top 12 items.
- Precision@12: Proportion of relevant items among the top 12 recommended items.
- Recall@12: Proportion of relevant items that have been retrieved in the top 12 recommended items out of all relevant items.
- F1@12: The harmonic mean of Precision@12 and Recall@12, which provides a balance between precision and recall.
Acknowledgements:
Dong Wang, Manan Shah, Myunghwan Kim, Akihiro Nitta, Siyang Xie
Join our community on Discord.
Connect with developers and data professionals, share ideas, get support, and stay informed about product updates, events, and best practices.