

Relational databases are the backbone of many industries, from healthcare and e-commerce to telecommunications and finance. These systems store data in multiple interconnected tables, which capture rich and complex relationships. However, leveraging this data for machine learning has traditionally required manually flattening it into a single table and performing hand-crafted feature engineering based on intuition — a process that is time-intensive, error-prone, and often discards valuable relational information.
In our paper, Relational Deep Learning: Graph Representation Learning on Relational Databases, we present Relational Deep Learning (RDL): a method that eliminates the need for manual feature engineering. Instead, RDL transforms relational data into a graph and applies Graph Neural Networks (GNNs) to learn directly from the data’s inherent structure. This approach makes it possible to build machine learning models that fully utilize relational data while streamlining workflows.
The Problem: Manual Feature Engineering
Using relational databases for machine learning typically involves the following steps:
- Flattening relational data: Joining and aggregating multiple tables into a single flat table.
- Feature creation: Designing specific features (e.g., "average transaction size" or "number of purchases in the last 30 days").
- Constant rework: Redesigning features whenever data distributions shift or new use cases emerge.
These steps require significant human effort and domain expertise, introducing inefficiencies and limiting scalability. Most importantly, manually flattening data often loses the intricate relationships that are central to the database’s value.
To give an example, we asked an experienced data scientist to solve a predictive task on a relational database by designing features and feeding them into a tabular LightGBM model, and these are the resulting features that were being used:

Most of the features are chosen arbitrarily based on “best intuition”. For example, the num_reviews feature only takes the global number of reviews into account but lacks recency information. last_review_summary_text uses a text embedding of the last review, but discards any reviews prior to that. Lastly, features that try to capture trends, e.g., num_reviews_trend, are based on a pre-chosen 6 month window and thus miss the flexibility to capture trend signals much more dynamically.
The Solution: Relational Deep Learning
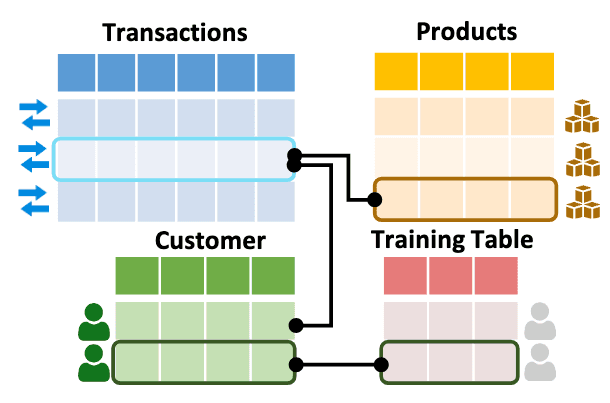
Relational Deep Learning avoids flattening by treating relational databases as graphs. Here’s how it works:
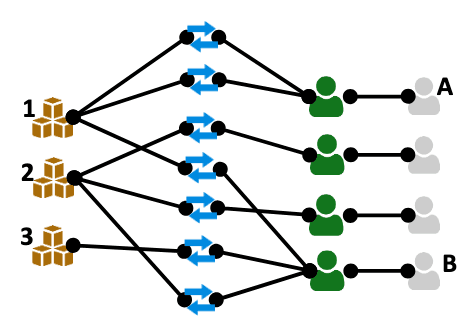
- Graph Representation: Relational tables are represented as a graph, where rows become nodes and relationships between rows (e.g., primary key<>foreign key relationships) form edges.
- Graph Neural Networks (GNNs) and Graph Transformers: GNNs propagate information across this graph, capturing patterns and dependencies between entities.
- End-to-End Learning: The entire process — from raw relational data to predictions — is automated, allowing models to learn directly from the graph representation.
This approach preserves the full structure of the relational data and allows models to uncover insights that manual transformations might overlook.
Key Advantages of RDL
- Maintains Relationships: By working directly on the relational graph, RDL avoids the information loss associated with flattening.
- Temporal Awareness: Ensures that predictions are based on the correct timeline, preventing models from using future data inadvertently.
- Scalability: Efficiently processes datasets with millions of nodes and edges, making it suitable for real-world applications.
- Flexibility Across Tasks: Supports a wide range of predictive tasks, such as classification, regression, and link prediction.
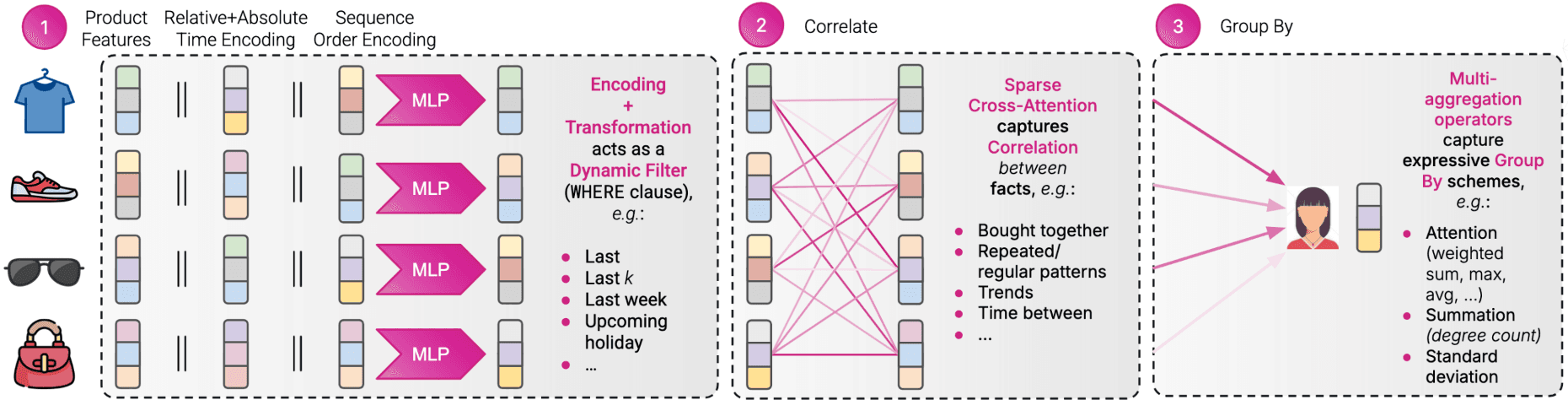
RDL provides a scalable, efficient, and versatile solution to the longstanding challenges of relational data. In particular, GNNs and their propagation schemes can be understood as learnable “Group By” operators that can dynamically (1) filter, (2) correlate, and (3) group interactions. By adapting to a given data distribution during training, they can find previously shown “hand-crafted features” on their own (and many more!), while not being bound by a data scientist’s imagination. This tree-stage approach have been proven to be highly effective. Firstly, the GNN can filter the set of interactions based on certain conditions such as product features, recency, seasonality, etc. Secondly, it computes sparse cross-attention on the filtered set to capture correlations such as “Bought together” patterns, repeated/regular patterns, trends, etc. Lastly, it performs multi-aggregation to merge fact representations into a single embedding tied to a specific user.
RelBench: A Benchmark for Relational Deep Learning
To advance this field further, we developed RelBench, a benchmarking suite designed for evaluating relational deep learning methods. RelBench includes:
- Diverse Real-World Datasets: Providing a comprehensive set of databases across a variety of domains, including e-commerce, Q&A platforms, medical, and sports databases.
- Predictive Tasks: Tasks range from forecasting customer churn and estimating lifetime value to predicting content popularity.
- Standardized Tools: A Python library facilitates dataset loading, graph construction, and model evaluation.

Applications of RDL
You can use RDL models practically anywhere you would use traditional predictive models. You can also create embedding models for relational data and use those models as part of a model training or generative workflow in even more use cases.
- E-commerce & Retail: Forecast customer behavior, optimize recommendations, pricing, and inventory by linking transactional data with reviews and browsing patterns.
- Healthcare: Predict patient outcomes and disease risks by integrating clinical records, lab results, and treatment histories.
- Finance & Banking: Enhance fraud detection and credit scoring by analyzing relationships in transaction histories and customer profiles.
- Telecommunications & Transportation: Improve churn prediction, network performance, and traffic management using call records, sensor data, and real-time usage patterns.
- Supply Chain & Manufacturing: Forecast demand, streamline logistics, and predict equipment failures by connecting orders, production logs, and sensor readings.
- Social Media & Entertainment: Uncover trends and personalize content by modeling user interactions, posts, and engagement metrics.
- Public Sector & Energy: Optimize citizen services and grid management through integrated government and utility data for better resource allocation.
- Cybersecurity & Insurance: Detect anomalies and manage risk by correlating logs, claims data, and external threat indicators.
Conclusion
Relational Deep Learning closes the gap between relational data and modern AI applications. It also drastically cuts down the time and expertise needed to create predictive or embedding models, especially by eliminating the need for manual feature engineering and extensive data preparation. With the introduction of RelBench, we hope to encourage further exploration and innovation in this space.
For more details, see our papers: Relational Deep Learning: Graph Representation Learning on Relational Databases and RelBench: A Benchmark for Deep Learning on Relational Databases
You can also start leveraging RDL right away using the Kumo platform, which provides an intuitive UI and SDK for developing and running RDL-based models directly on your relational database or data warehouse.
Join our community on Discord.
Connect with developers and data professionals, share ideas, get support, and stay informed about product updates, events, and best practices.