

Summary:
- Delivered predictions routinely for hundreds of millions of users
- Increased GMV by ~$100M
- Decreased serving costs by 80%
Challenge
A Fortune 500 on-demand food delivery service wanted to increase its revenue by better personalizing their recommendations. In the hyper-competitive landscape of food and convenience delivery services,
relevant recommendations play a pivotal role in driving user engagement. These recommendations not only serve as reminders to users about the myriad of services available at their fingertips, but also aid in personalizing the user experience, promoting new offers, and ensuring top-of-mind recall. A well-timed, relevantly served recommendation can be the difference between a completed
order and a lost opportunity, making it an essential tool for such businesses.
This client worked with Kumo to power the personalization of their push notifications for serving hundreds of millions of client’s users. By using Kumo platform, they achieved significant improvements in engagement metrics, driving ~90k incremental MAU and projected an ~$100M increase in GMV (gross merchandise value) all while reducing their serving costs relative to an existing in-house model by 80%.
Our client’s business goal was to personalize the notification content for better user engagement, aiming for more MAUs (users who order at least once per month). Before Kumo came in, such
notifications had already been served by making Rest API calls to the recommendation service designed for a different use case owned by the other team. This approach had a few challenges. First, as the use case was different, an effective infrastructure choice and an optimal model were also different. Second, since the content of notifications could keep evolving to engage their users better and timely, relevant personalization should be adjusted to that. However, the dependency on the recommendation service meant for a different purpose would limit the power of personalization specific to the notification.
The client worked with Kumo to productionize the recommendation service quickly and easily. For the starting point, they targeted the personalized new store recommendation problem so that they could
consume Kumo’s recommendation outcome to serve “Try Something New” type of notifications.
This new store recommendation problem had some challenges. The client’s users often order from the same stores again and again, so order data from new stores is much sparser. Also, since all the stores that users ordered from in the past are not eligible for this recommendation, frequency-based statistical models cannot work for this problem. The model for this recommendation should
be great at generalization.
To simplify the problem and make it generally usable, the client formulated it to predict all the stores that each user will order from in the next 7 days. 7 days was chosen because it was related to the cadence of this type of notification. Once they obtained the recommendation about all the stores, they could filter out any past stores to serve the new store recommendation.
Data Setup
Our client shared their data through AWS S3 and wrote back the output of predictions into the S3. To tackle this problem, 3 datasets were used: USERS, ORDERS, and STORES spanning across the last 6 months for all the hundred millions of users.
In addition to those minimal datasets, the client also shared various datasets that could represent user interests, intents, and preferences – such as store views, ratings, search queries, and saved stores. In overall, there were 20B+ records of data.
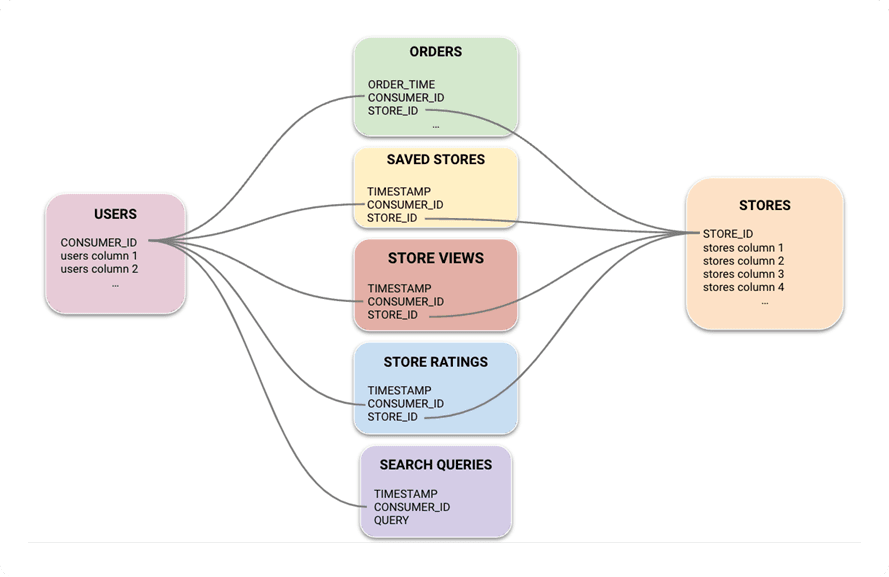
Figure 1: Data schema used for store recommendation
Kumo Setup
On the Kumo platform, our client used an out of the box connector to import raw datasets from AWS S3. Note that no features (e.g. ‘count of orders in the last 7 days’) were engineered.
Instead the raw data tables were connected into the above graph. Our client created the following Predictive Query to define the ML model:

Predictive Query used inside Kumo
The SQL-like statement predicts all the distinct stores that will appear in the ORDERS table in the next 7 days for each user. The Kumo platform handles this prediction task as a link prediction
problem in the bipartite graph between CONSUMER_ID and STORE_ID by regarding links as orders in the next 7 days.
Model Improvement
Our client quickly deployed the model to production and ran an A/B test. They observed that the recommendation from Kumo lifted the conversion rate while the impact on key business metrics like MAU was neutral.
Given the outcome of the A/B test, the client wanted to iterate to improve the model quality. Since they used large and rich data, one straightforward direction would be to increase model capacity, which means using larger embedding dimensions, deeper input- and output-MP layers, and sampling a higher number of neighbors in the GNN layers. They created a new Predictive Query to train this larger model by configuring the Advanced Options accordingly:

This configuration overrides the number of neighbors used in GNN by 64 (num_neighbors), and makes all the dimensions of embeddings (lp_embedding_dim) and hidden layers (channels) 128, which doubles over the default value of 64. Furthermore, the number of MLP layers is set to 2 for both input (num_pre_mp_layers) and output (num_post_mp_layers). This approach obtained about 6% better performance than the initial model in terms of MAP@10 (for new store recommendation).
However, the client could improve the model further. While examining the learning curves shown below, which show the MAP@12 metric computed on the validation set with respect to the number of training iterations, they noticed an important detail. The settings for maximum iterations and epochs of training were enough for the initial model to converge (i.e., the learning curve was almost saturated), but they were not enough for the higher capacity model – the learning curve was not yet saturated. This clearly implied that more iterations and epochs of training would improve the model performance.
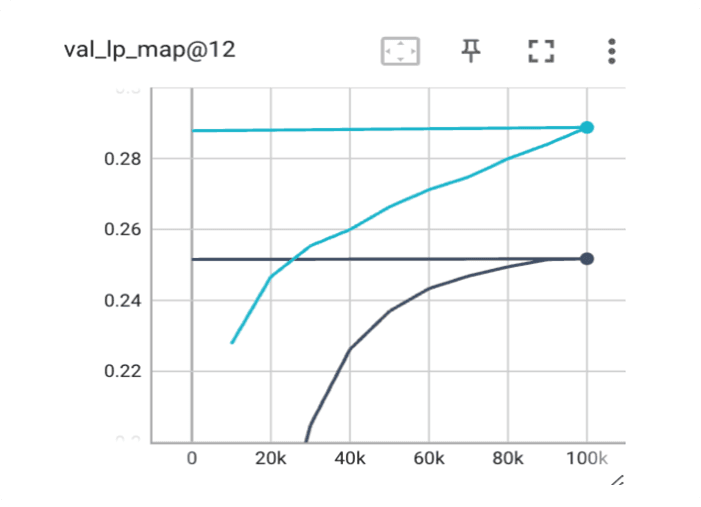
Figure 2: Learning curves between for two models
To allow longer training, the client added the following Advanced Option parameters to increase the number of steps per epoch as well as the max epoch size:

By adding this to the setup, the client achieved 15% further improvement in MAP@10, which means this model is 22% better than the initial one. On the other hand, Kumo platform also provides a ranking algorithm module – link_prediction_ranking which focuses on recommendation beyond the use of embeddings. This algorithm incorporates the architecture of Identity-Aware GNNs [1] into the Kumo framework, and drastically improves the performance of direct prediction outcomes, while not improving the embedding performance. This module can be used when predictions (i.e. store recommendations) are directly consumed instead of being computed from the embeddings via the dot product. This different algorithm can be tested by setting the following Advanced Option parameter:
`module: link_prediction_ranking`
Amazingly, this algorithm selection along with previous improvements on capacity and training gives an 80+% improvement of MAP@10 over the baseline.
To summarize, he client iterated and improved the model performance as follows:
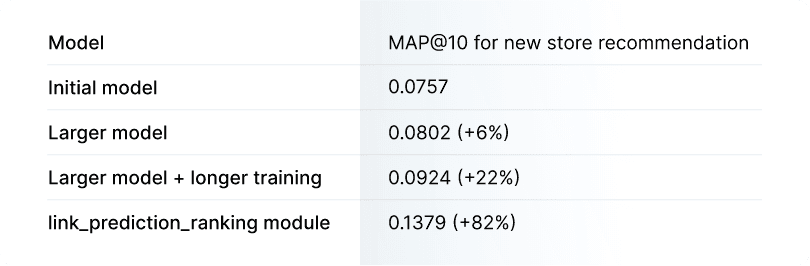
Model performance improvement over model iterations
Road to Production:
Deployment to production for A/B testing
Offline estimation of the actual business impact for this use case is very hard. First, due to sparse historic observations for which stores were not recommended to each user, it was hard to objectively determine if a given recommended store was good or not. Second, notification impact could be affected by many other external factors beyond the recommended store such as send time, message content, and so on. Hence, the simplest way to check the performance was to deploy a new model to production and run an A/B test.
Before deploying the model to production, it was crucial to determine how the recommendation output would be consumed downstream. This might depend on engineering or business constraints such as SLAs, or be determined by downstream usage of its output, such as applications of additional ML or filtering modules on top of the recommendation output. New store recommendation use case required a few business constraints – the recommended stores must be new stores for a given user, must be open at time of recommendation, and must be geographically reachable by the given user. Our client decided that the easiest way to work under these constraints was to have two jobs: the first job produces user and store embeddings, and the second job ranks stores via a dot product between store and user embeddings and then applies the relevant business constraints.
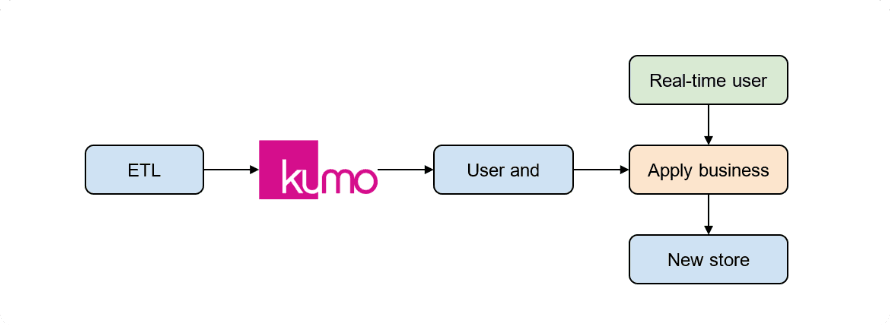
Figure 3: Illustration of Kumo output consumption
Once the consumption strategy of Kumo outputs was defined (See Figure 3 for more details), our client created a job to trigger the batch prediction Rest API for a given Predictive Query named

Since the job was orchestrated by a standard framework like Airflow, our client used the dated path like “s3://bucket/path/YYYYMMDD” to easily maintain the Kumo output. This practice is common in the industry so that our client could place proper sensors on job output artifacts and monitor any operational issues such as too few predictions being generated.
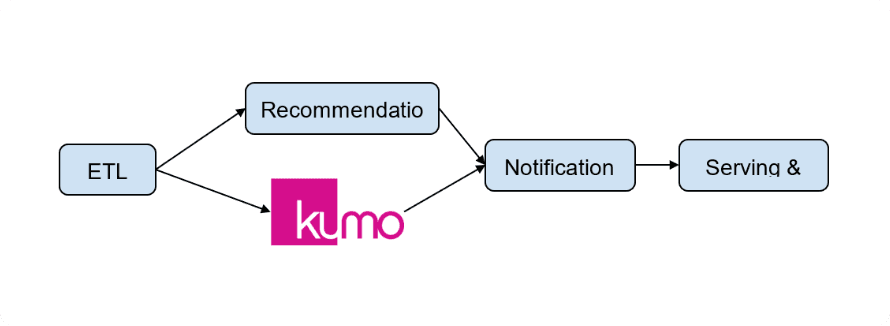
Figure 4: Workflow for A/B test with Kumo platform
For A/B testing, in addition to the internal existing recommendation module, our client added a job for a batch prediction REST API call to Kumo, all from within the existing ML serving pipeline. When they would not need the internal recommendation module any more, they could easily remove the unnecessary job later.
Controlling batch predictions
Our client now included the batch prediction job into the pipeline. This pipeline worked well, but there were a couple of engineering challenges: 1) it takes 24 hours to produce the output for multi-hundred million users. 2) only a quarter of users are eligible for mobile push notifications, so producing batch prediction outcomes for all the users is a waste of resources. Kumo provides the solutions for both challenges.
First, Kumo batch prediction Rest API takes the parameter of parallelisms to speed up the end-to-end time. Second, our client can apply filters at the batch prediction so that they can produce the predictions (embeddings) only for a subset of users. They needed to add the following parameters into the batch prediction job:

Here the parallelism is set to 4 through num_parallel_workers_limit. This reduced the end-to-end runtime by more than 50%. Moreover, the following filter override argument, ‘entity_filter_override’:”Users.NOTIF_ELIGIBLE = 1″, constraints batch prediction output only to users satisfying the NOTIF_ELIGIBLE = 1 condition. By combining both improvements, our client reduced the end-to-end runtime from 24+ hours to the 4~5 hour level.
This additional filter parameter provided a lot of flexibility for operation. For instance, our client wanted to use the same recommendation job not only for mobile push notifications but also for email marketing. However, email marketing is applicable to all the users unlike mobile notifications and requires a longer cadence of update.
This could easily be set up via job orchestration. Our client’s use case required batch predictions for mobile notifications every other day and one weekly batch prediction for email marketing. In this scenario, the Predictive Query can be reused by scheduling the jobs as follows.
- Every Monday/Wednesday/Friday: run the job with the additional entity_filter_override parameter
- Every Saturday: run the job without the filter
New A/B test and Impact
Given the success of the above model improvement iteration journey, the client set up a new A/B experiment with the improved model. However, recall that the existing pipeline consumes the embeddings and obtains store rankings via the dot product. Consequently, the deployment of the larger but still embedding focused model was straightforward since the consumption strategy is the same. On the other hand, the deployment of the link_prediction_ranking model, which provides the largest boost in model quality, required some additional engineering development since we are no longer consuming embeddings but instead predictions directly. To expedite the impact on business metrics, our client decided to deploy the larger model (trained for longer) first – making sure that the model quality improvements were enough to show value in the A/B test. At the same time they were continuing to develop the proper pipeline to consume the prediction outcome from the link_prediction_ranking model directly.
The A/B experiment ran for 4 weeks. The Kumo model achieved about 1% conversion improvement compared to the client’s internal model (for the given particular notification), which has been developed for multiple years. And this 1% conversion improvement was able to move even MAU by a statistically significant factor, which can be translated into about 100M$ of annualized GMV. Furthermore, Kumo could reduce the overall model serving cost by 80% as opposed to the infrastructure cost of the existing internal model.
Conclusion
Despite not deploying the best performing model yet, Kumo was able to provide huge revenue gain with additional cost reduction to boot, in a real-world business application. The Kumo model variant has since been ramped to 100% in the client application and continues to serve new store recommendations today. We are still collaborating with this client to provide more business value by integrating the link_prediction_ranking module, as well as continuing to improve models through adding more data and expanding our available functionality.
References
[1] Identity-aware Graph Neural Networks, Jiaxuan You, Jonathan Gomes-Selman, Rex Ying, Jure Leskovec, AAAI’21
Join our community on Discord.
Connect with developers and data professionals, share ideas, get support, and stay informed about product updates, events, and best practices.