
Impact:
- From loading raw data to delivering production-ready predictions in 1 week
- 24% Precision@12 for new item recommendation
- 7% lift in Precision@12 for past item recommendation
Problem
A leading grocery chain wanted to increase their sales by sending personalized physical flyers with a dozen coupons to their clients to encourage them to buy things they might want to buy.
They wanted to encourage clients to buy items that they have purchased in the past as well as encourage them to buy new items that they have never purchased before.
Our client solved this recommendation problem by predicting which items would be purchased by each user for the future time period of interest. Kumo allowed them to easily frame and solve this problem as a Link Prediction task, predicting links between users and items in the bipartite graph.
Data Setup
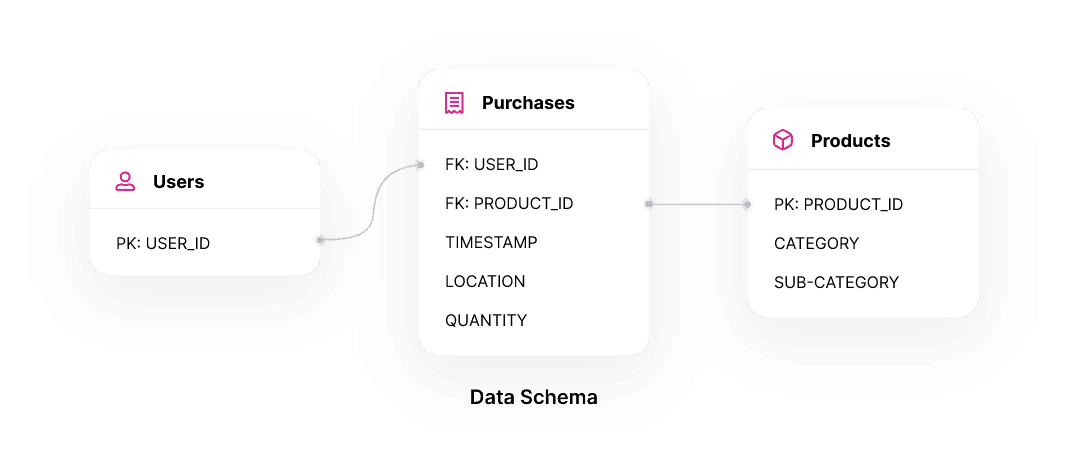
The client’s user uploaded three tables to the Kumo platform.
- A dimension table with millions of their client IDs. They didn’t have any other user attributes but Kumo could benefit from those when available.
- A dimension table with all their tens of thousands of products they sell and the attributes they have about those products including product department, product category, product sub-category, product size.
- A fact table with all the several hundreds of millions of historical purchases made by their users and attributes about each transaction including location and quantity.
Kumo Setup
The client then created a simple graph inside of Kumo following their data schema where their user and item tables were connected to the transaction table using the primary and foreign keys on those tables.
After the graph setup, the client created a Predictive Query to tackle the prediction task. Here is one tricky situation for this client’s use case. Recall that our client would use the recommendation for the physical flyers. This means that coupon flyers can take up to a week to be delivered to their client’s physical address. Because of that, they needed to make predictions at the beginning of each month specifically for the last 3 weeks of the month (when the recipient will be able to use the coupons).
This prediction task could be easily described by our Predictive Query language as follows:

LIST_DISTINCT(transactions.item_id, 7, 28, days) represents all the items that will be purchased between next 7 days and 28 days. The client wanted to predict these, and Predictive Query allowed them to directly describe the prediction task.
Model Improvement
GNN ARCHITECTURE
Since the quality of recommendation ranking is the most important thing for this use case, the user configured Kumo to use a link_prediction_ranking module that integrates into the model architecture and provides the best ranking performance at scale. This can be configured using advanced options in the platform.
HYPERPARAMETERS
The client aimed to use a unified recommendation framework to tackle two sub-recommendation tasks.
- Repeat Item Interaction: recommend items the user has interacted with in the past
- New Item Discovery: recommend items that the user has never interacted with
The client realized that their graph was very dense (very high edge degree). This was preventing them from learning the best model to solve the “Repeat Item Interaction” problem.
The main reason this happened was that people tend to buy various grocery items and this long-tail density made it a bit harder for our normal AutoML ranges to find the best solution.
To address this, they increased the amount of neighbors of the target table to sample (for a single entity) in the advanced options.
This helped them control how many neighbors to sample from the target when building the GNN. It is important to look at the edge degree stats and increase this value when you have a very dense graph.
Increasing this helped them quickly improve the general model performance by 5%.
The client then realized that their data was very heavy on “Repeat Item Interaction” edges but had very few examples of “New Item Discovery”. This was preventing them from learning the best model to also solve the “New Item Discovery” problem.
To address this, they increased the dimension of the entity embeddings being learned by the model and also the dimension of the layers in the GNN both using the advanced options in the platform.
Bigger embeddings improves the model capacity to learn more complex representations of the products and the users in the data (at the cost of slowing down training).
Increasing this a bit gave them a 15% lift on the new item discovery problem right away.
The client then also experimented with other advanced options to help find the best configuration
- Increase the coefficient of embedding loss applied to train ranking-based link prediction to emphasize learning of shallow embeddings.
- Increase the number of neighbors to sample for each connection in each hop in the graph. They used a 2 hop GNN for this problem so they had to increase it for both hops.
- Increased the number of steps to train in a single epoch. Setting this to something very large causes it to not evaluate too frequently and thus slowing the model down.
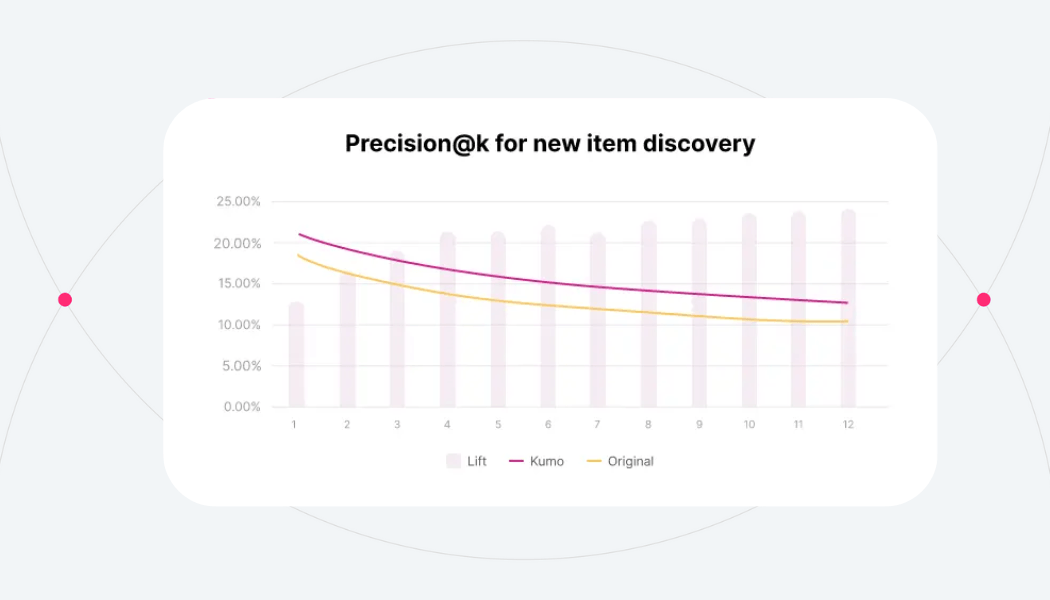
Final results and impact
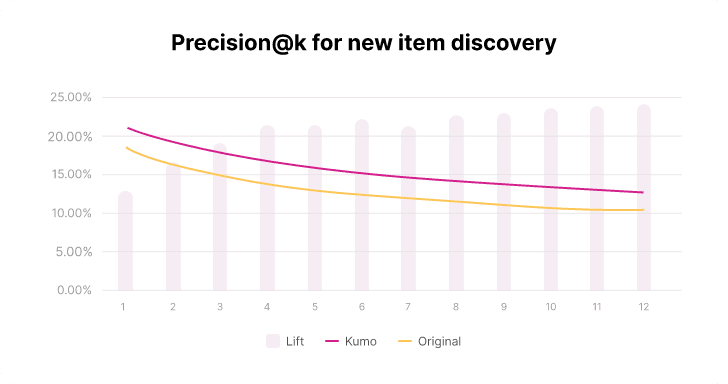
The predictions produced in Kumo were significantly more precise than those produced by the client’s internal model. They saw a 24% lift on PRECISION@12 for the new item discovery problem and a 7% lift on PRECISION@12 for the repeat item interaction problem. Their previous models were custom made and it took them several years to develop and several engineer hours a week to maintain. The Kumo model took 1 week to develop and deploy in production. From loading data, to modeling iterations, to business results. Minimal engineer hours are required to maintain it, since Kumo provides the needed SLAs for everyone’s peace of mind.
Predictions
Once the model is trained they use Kumo to make predictions at the beginning of the month for all future sales in the last three weeks of that month. The prediction job produces a dozen product recommendations for each of their users in a matter of minutes.
Join our community on Discord.
Connect with developers and data professionals, share ideas, get support, and stay informed about product updates, events, and best practices.