


Written by Youngchul Joo and Sang Ann, KumoRFM Hackathon participants
In this technical blog post, Youngchul Joo and Sang Ahn explore how they built an electricity demand forecasting solution using KumoRFM. Their project, From Megawatt Errors to Millions Saved, demonstrates how KumoRFM can empower municipal utilities to achieve near state-level forecasting accuracy without domain expertise or months of modeling. By leveraging KumoRFM’s foundation model for business data, their two-person team reduced forecast errors by nearly 14 percent, showing how small teams can drive million-dollar savings in the energy sector.
Introduction
“Using Kumo RFM was a truly astonishing experience. We established a strong baseline from raw data in minutes, then added some basic features and beat a state-level benchmark. The platform's ability to eliminate the modeling and tuning bottleneck, allowing us to get state-of-the-art results without deep domain expertise, all just within a few days, was truly a game-changer.”
Every day, municipal utility operators face a multi-million dollar question: how much electricity will our community need tomorrow, next week, or next month? Guess too low, and you risk blackouts. Guess too high, which is far more common and you are forced to sell excess power back to the wholesale market at a significant loss. For smaller public utilities with limited resources, this financial drain can significantly impact budgets.
The core of the problem is that creating highly accurate forecasts has traditionally been the domain of large organizations with deep pockets and specialized data science teams. This work is critical for financial stability and grid reliability, directly benefiting the communities these utilities serve. This project demonstrates a new, more accessible path to state-of-the-art forecasting, empowering organizations of all sizes to make smarter, more cost-effective energy decisions.
Our Approach with Kumo RFM
Our goal was to generate hourly electricity demand forecasts with Kumo RFM for the San Francisco Bay Area that are comparable to, or perhaps even better than, those provided by the California Independent System Operator (CAISO).
To generate predictions, the conventional data science workflow would look like the following.
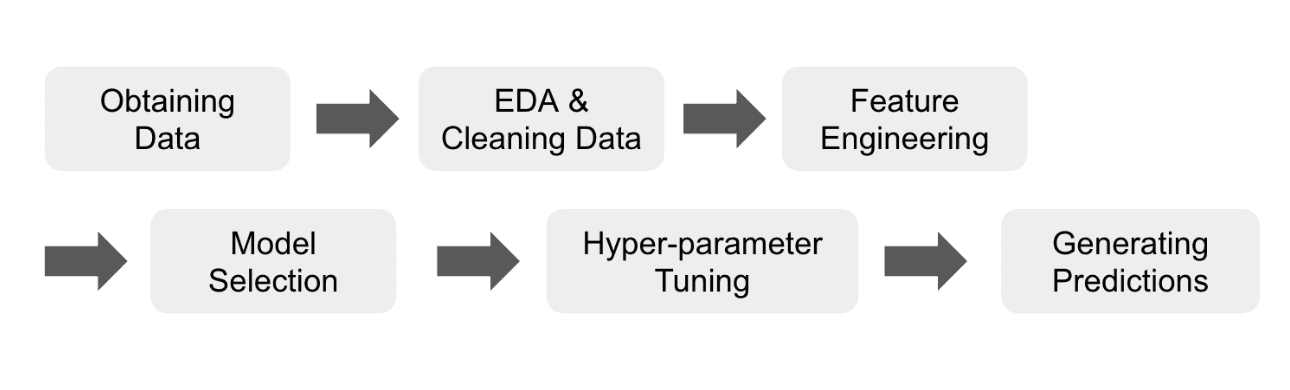
Where each of the intermediate steps can take hours, if not days or weeks. However, the innovation of Kumo RFM allowed us to abstract away all the intermediate steps, for a dramatically shorter amount of time needed for predictions.

By providing a powerful, pre-built modeling foundation, Kumo RFM eliminated the time-consuming tasks of data cleaning, feature engineering, model selection, and hyper-parameter tuning. This streamlined process enabled our two-person team, neither of whom are energy experts with domain knowledge, to move incredibly fast and generate predictions for electricity demand.
Experiments & Results
Datasets Used
We used a combination of publicly available data, all geographically aligned to the SF Bay Area:
- Historical hourly electricity demand (actuals and forecasts) from CAISO
- Local weather data MeteoStat
- Locations of Electric Vehicle (EV) charging stations NREL
- Data on Distributed Generation (DG), primarily local solar installations California DG Stats
Evaluation Metrics
We used standard metrics used for prediction tasks like Mean Absolute Error (MAE), Root Mean Squared Error (RMSE), and Mean Absolute Percentage Error (MAPE) to evaluate our forecasts.
Setup
In our initial round of experiment, we applied Kumo RFM to the data with no data cleaning or feature engineering. The generated forecasts had MAE and RMSE that were around 100%-200% higher than those from CA ISO. While not state-of-the-art, this result was incredibly impressive given that there was minimal effort from our end and we only used publicly available data. It would be reasonable to assume that CA ISO has higher-quality proprietary data and probably spent months of time and resources to develop their prediction algorithm.
However, we were interested in whether we could improve the forecast quality with additional effort. We applied standard, foundational time-series feature engineering techniques that any data scientist could think of, like creating lagged values, moving averages, and cyclical features to represent the time of day and year. Our modified workflow was:
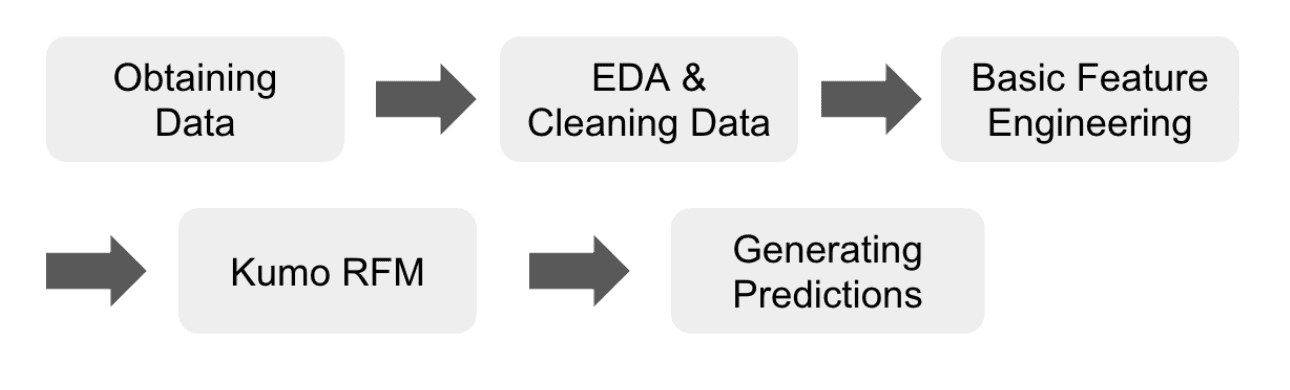
Key Results
The effect of adding basic features was dramatic. Kumo RFM was able to leverage these simple, new signals to produce a forecast that was more accurate than the official CAISO benchmark.

For randomly selected 1,000 timestamps, our model with basic feature engineering achieved:
- A 13.84% reduction in Mean Absolute Error (MAE) for 7-day ahead forecasts, from 222.1 MW to 191.4 MW.
- A 17.81% reduction in Root Mean Squared Error (RMSE) for 7-day ahead forecasts, indicating far fewer large, costly errors.
Applications & Impact
The real-world application of this work is clear: helping municipal utilities reduce financial waste. A more accurate forecast allows a utility to purchase power with confidence, minimizing the need to sell excess capacity at a loss. Even a 1-2% improvement in forecast accuracy can translate into hundreds of thousands, if not millions, of dollars in annual savings for a mid-sized utility.
By making this level of accuracy accessible without a massive investment in a specialized, domain-expert team this approach allows public funds to be reallocated from operational losses to essential community services.
Lessons Learned
- What worked well: The ease and speed at which Kumo RFM could provide forecasts was astounding. We could obtain forecasts within minutes of getting the data. While these forecasts were not state-of-the-art, they were definitely good enough to serve as solid baselines. Basic feature engineering, which only took a few hours, amplified Kumo RFM’s predictive abilities and allowed us to generate high-quality forecasts.
- What was challenging: Beating a well-resourced, professional benchmark like the CA ISO forecast is a difficult task under any circumstances.
- What surprised you: The biggest surprise was the "bang for your buck." We were amazed at how a set of standard, non-domain-specific features could beat a highly specialized forecast when paired with Kumo RFM. It proved you don't need to be a domain expert to get state-of-the-art results.
Conclusion
Our investigation revealed a new and powerful paradigm for data science teams. Kumo RFM's real innovation is how it streamlines the end-to-end workflow. It provides an instant, valuable baseline with raw data and then acts as a powerful engine that magnifies the impact of fundamental data science practices. This democratizes access to state-of-the-art predictions for organizations with limited resources, proving that any skilled data scientist can tackle highly specialized problems that, without Komu RFM, would require a significantly larger team with more resources.
Join our community on Discord.
Connect with developers and data professionals, share ideas, get support, and stay informed about product updates, events, and best practices.