


Written by Azin Asgarian and Frederik Dudzik, members of Georgian’s AI Lab
In this technical blog post, Azin and Frederik share how they used KumoRFM to build KumoVC, a suite of predictive tools that help identify high-potential startups, best-fit investments, and ideal advisors, placing Georgian’s AI Lab among the top 10 finalists at our KumoRFM August Hackathon in San Francisco.
Their article illustrates how KumoRFM transforms venture data into instant predictions, streamlining investment decision-making and accelerating deal discovery.
Introduction
Georgian is a growth-stage investor that aims to help Georgian portfolio company founders scale faster through initiatives across technology, customer success, finance, community, and more. At the heart of our collaboration with our founders is the Georgian AI Lab: Georgian’s in-house team of ML practitioners. The AI Lab helps portfolio companies adopt emerging technologies, and also builds internal tools designed to give our investment team sharper, faster ways to make decisions.

Finding fast-growing companies to invest in, however, is not an easy task. Venture capital is a constant search for signals in the noise. We aim to find companies on the rise that are likely to raise soon and best fit our investment mandate so that we can engage at the right time. We also try to uncover meaningful ways to build connections with potential portfolio companies.
The raw data to help us find these signals already lives in part in Georgian’s internal data warehouse—companies, funding rounds, people, and their affiliations. But turning this data into actionable insights has traditionally been a slow, resource-heavy process spread across teams and requiring months of ad-hoc data wrangling, feature engineering, model building, and ongoing maintenance.
That’s why we joined Kumo.ai’s hackathon: to see if we could cut through the complexity and use our relational data more efficiently and effectively. The rest of this post walks through how we applied Kumo’s Relational Foundation Model (KumoRFM) to reason over our temporal, multi-table data and what we observed in practice.
KumoVC
For the hackathon, we built and demoed KumoVC, a suite of three use cases that helped us answer the following questions:
- Which companies are likely to raise soon?
- Which companies may be the best fit for Georgian?
- Which advisor in our network is the right fit for a company?
We did not use Georgian’s proprietary data for the hackathon, and instead created a synthetic dataset to mirror the kinds of data we typically work with. With GPT-5, we generated four linked tables: companies, funding rounds, people, and affiliations. To use KumoRFM, we then loaded these tables and connected them to create a KumoGraph (shown below).
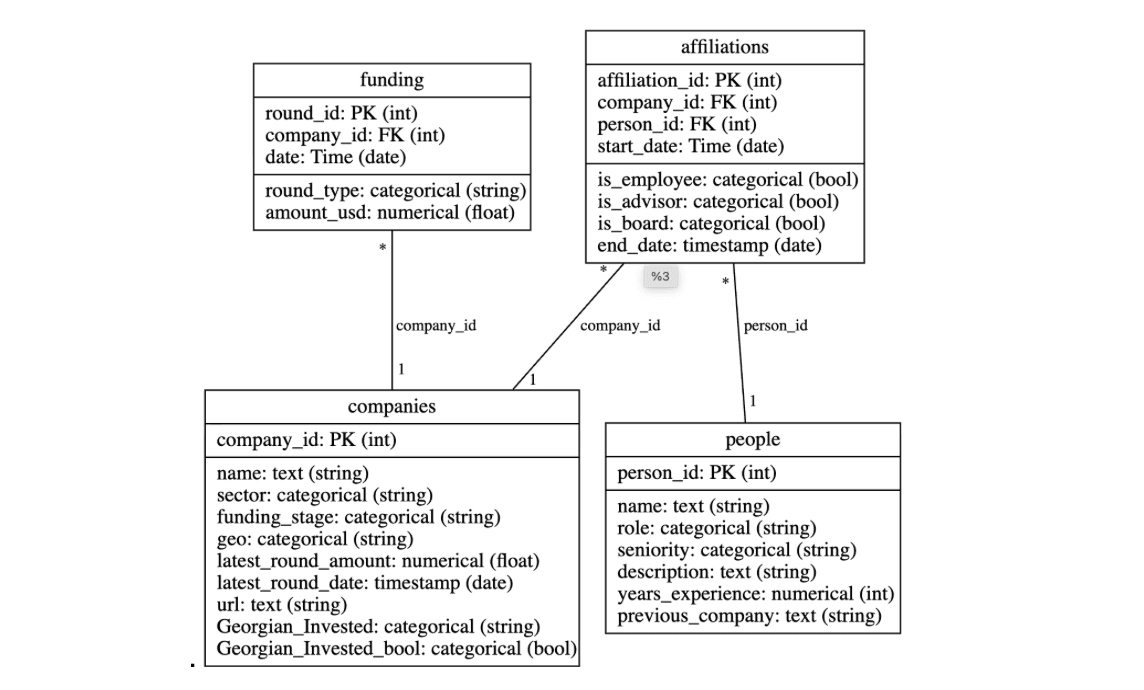
We were now ready to run our predictive tasks. The significant effort generally required in ETL and feature engineering (e.g., flattening, cleaning, joining, and manually processing data) was reduced to declaring a graph using KumoRFM. KumoRFM works directly with graph data, which preserves the intrinsic relationships across tables, allowing predictions to run almost immediately without any need for feature engineering (and hence protects against information loss).
With the KumoGraph in place, we initialized a KumoRFM model to power predictive queries and put KumoVC to the test. To make the results easier (and more fun) to explore, we pushed the outputs into a simple, lightweight interface, which you can see in the Demo section.
The Use Cases
Use Case 1: Future Funding (Regression)
For the first use case, we framed a regression problem: “estimating how much startups are likely to raise in the next 180 days”.
This highlights which companies are most likely to raise within a particular timespan, giving our investment team time to build the investment case and prepare sharper questions around runway, milestones, and lead dynamics. The intended result is better-timed engagement with prospective companies and a reduced risk of missing future opportunities.
1PREDICT SUM(funding.amount_usd, 0, 180, days)
2
3FOR EACH companies.company_idUse Case 2: Invest Fit (binary classification)
For the second use case, we framed a binary classification problem: “predicting which companies Georgian is most likely to invest in.”
This helps us identify the companies most relevant to Georgian given our investment mandate, generating a ranked list of opportunities across the funnel. The Invest Fit classification can assist our investment team by prioritizing inbound outreach, assigning the right investor, and de-prioritizing companies that are not a clear fit. The intended result is to surface more valuable opportunities that lead to investment while increasing the efficiency and effectiveness of our investment team.
1PREDICT companies.Georgian_Invested_bool
2FOR EACH companies.company_idUse Case 3: Advisor Recommendations (recommendation)
For the third use case, we framed a recommendation problem: “identifying the top-K non-employees (within the last 365 days) who could serve as advisors for a potential or existing portfolio company.”
This can assist in answering the question of who in our network is best positioned to advise or make introductions on behalf of a portfolio company or to a potential portfolio company, producing ranked candidates by role and seniority. The intended result is to connect founders with the right advisors and deliver value to Georgian’s portfolio and pipeline companies.
1PREDICT LIST_DISTINCT(affiliations.person_id, 0, 180, days) RANK TOP 3FOR EACH companies.company_idWHERE COUNT(affiliations.* WHERE affiliations.is_employee = FALSE, -365, 0, days) > 0Demo & Results
Since we used synthetic data, we couldn’t run a rigorous quantitative evaluation. Instead, we focused on qualitative testing to see how KumoRFM performed in practice. Even with this lighter approach, the results were impressive enough that we’re now testing Kumo with Georgian’s proprietary data and running more thorough in-house evaluations.
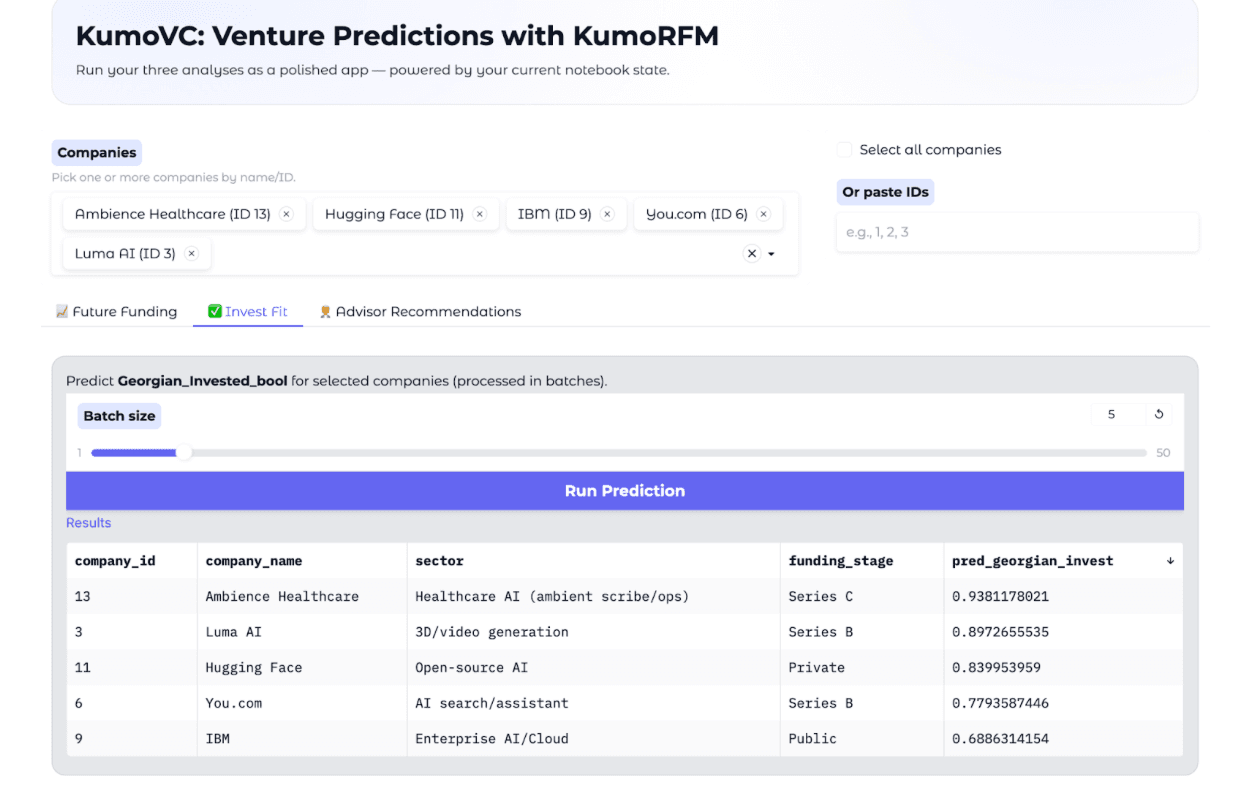
A few findings stood out right away. When we reviewed the predicted list of companies most likely to be a fit for Georgian investment, one of the top results was Ambience Healthcare — a company Georgian recently invested in. That was a strong and validating signal. At the other end of the spectrum, IBM appeared at the very bottom of the list, which also made sense: as a large public company, it sits far outside our investment mandate and sweet spot. These examples gave us confidence that the model was able to capture meaningful patterns, even with synthetic data.
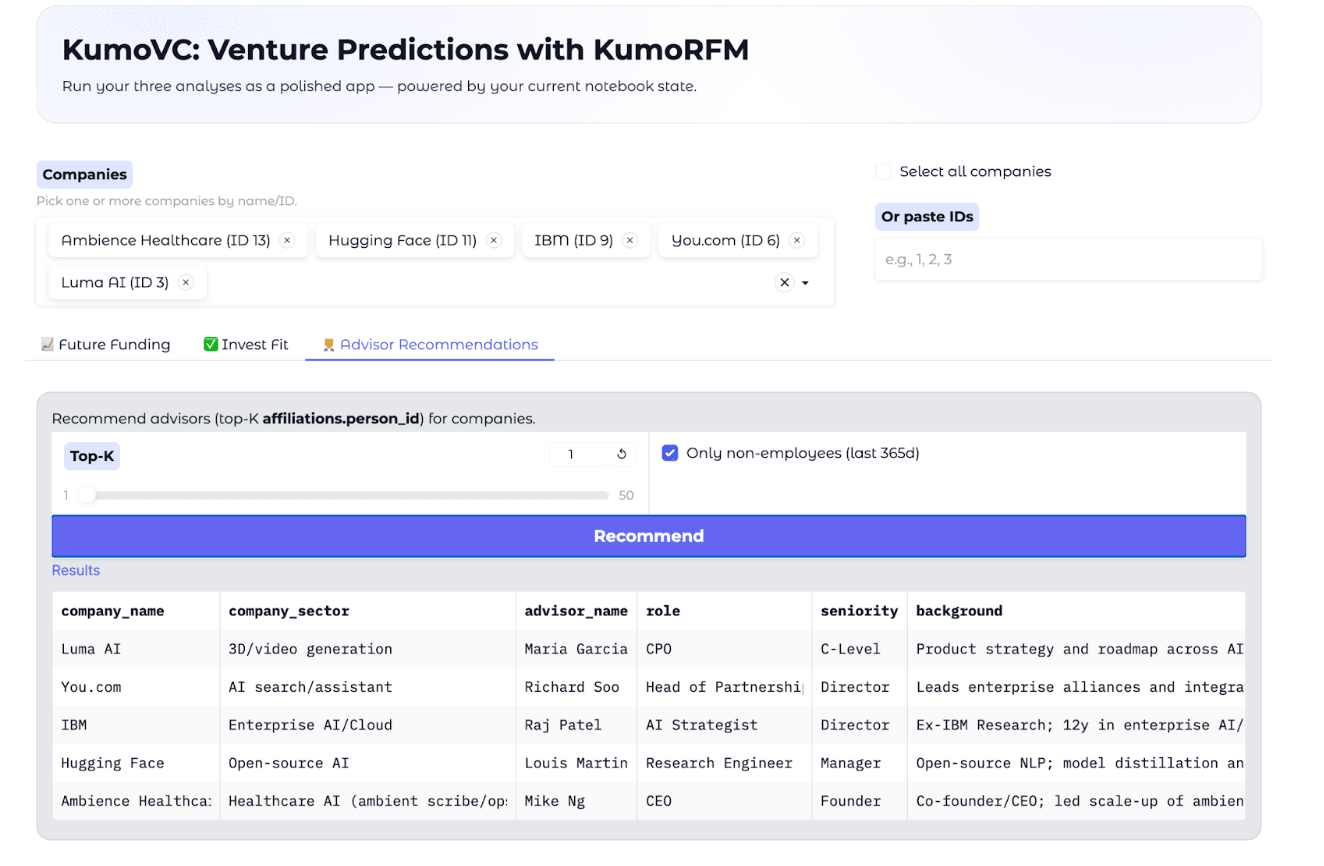
The advisor recommendation use case was equally interesting. While the profiles were synthetic, the relationships highlighted by KumoVC showed logical, realistic patterns. For instance, the system suggested a research engineer with expertise in open-source NLP and model distillation as an advisor for Hugging Face—exactly the kind of background that would add value to such a company. Similarly, IBM’s recommended advisor was an AI Strategy Director and former IBM employee, which aligned with what you’d expect in a real-world scenario.
Taken together, these signals reinforced our belief that KumoRFM can uncover insights that are both relevant and actionable. Even with synthetic data, it pointed us toward companies we are interested in, away from those that don’t fit Georgian’s investment thesis, and toward advisors whose backgrounds aligned with specific third party company needs.
Lessons Learned
What worked well and surprised us:
- Instant predictions: In our opinion, creating a KumoGraph was simple and allowed us to skip the process of cleaning, processing, and joining tables, reducing what historically would take us weeks of building and maintaining bespoke models to a few hours. We were able to start running predictions almost instantly.
- One setup, many use cases: The same graph powered multiple use cases with no extra configuration, saving more time and effort.
- Accessible for everyone: PQL was simple enough for anyone on the team to pick up, not just data scientists, allowing more people to run predictions on their own.
- Great support: Kumo’s documentation and team were excellent. Most of our questions were answered on their site or quickly in Slack.
What we found challenging:
- PQL queries: Crafting and validating the right queries took some iteration, but it was a valuable learning experience that helped us better frame predictive tasks.
- Setup issues: We ran into some installation challenges at first, but switching to a cloud environment solved the problem and kept us moving quickly.
- Synthetic data: Working with synthetic data and limited time meant we couldn’t run a full evaluation.
Conclusion
We were excited to demo KumoVC at Kumo’s hackathon, and we’re proud that Georgian’s AI Lab placed in the top 10 finalists (out of 140+ participants).
In the past, we relied on complex pipelines and custom machine learning models for lead qualification (a burden that frankly wasn’t worth the results). With KumoRFM, we see the potential to turn our warehouse into a steady stream of ranked, defensible suggestions that guide where we spend time, when we reach out, and who we bring to the table without spinning up a new model for every question.
KumoRFM’s approach for generating insights from relational data (e.g., using graph neural networks and the predictive query language) makes it appealing for a small data products team like ours. We see opportunities to extend our internal tooling with Kumo at minimal cost. On the same relational spine (companies ↔ rounds ↔ affiliations), we produced interactive signals that the Georgian investment team were able to use immediately resulting in a faster, more auditable way to focus investor time. We’re actively exploring how best to bring KumoRFM into our internal workflows.
If you remember one line: Don’t build a model; ask a predictive question.
Join our community on Discord.
Connect with developers and data professionals, share ideas, get support, and stay informed about product updates, events, and best practices.