
A quiet paradigm shift is underway in machine learning. For most of the last decade, progress came from improving how we engineered and processed features, such as using smarter aggregations, deeper networks, and better optimizers. But these methods all shared a limitation: they treated each record as independent, ignoring the relationships that actually drive behavior.
Now, a new class of models is redefining what’s possible. Graph Transformers represent the next leap in predictive accuracy. They learn directly from how entities interact, influence, and evolve together over time. In fraud detection, that distinction is critical. Fraud doesn’t occur in isolation but spreads through connections such as shared devices, linked merchants, and coordinated transaction networks. Graph learning captures these connections directly, revealing coordinated fraud patterns that row-based models overlook.
Kumo operationalizes this breakthrough for data science teams. Its declarative Graph Learning SDK integrates natively with python-based data science tools, letting teams define complex relational models with just a few lines of code. Under the hood, Kumo’s high-performance backend trains Graph Transformers at massive scale, across tens of billions of nodes and edges while maintaining temporal correctness, enabling organizations to achieve research-grade performance without building or maintaining specialized infrastructure in-house.
From Transactions to Relationships
Traditional fraud detection models, such as boosted trees, DNNs, or RNNs, represent the world as flat tables: each transaction, account, or device is treated as an independent row, and the model predicts whether that row looks risky.
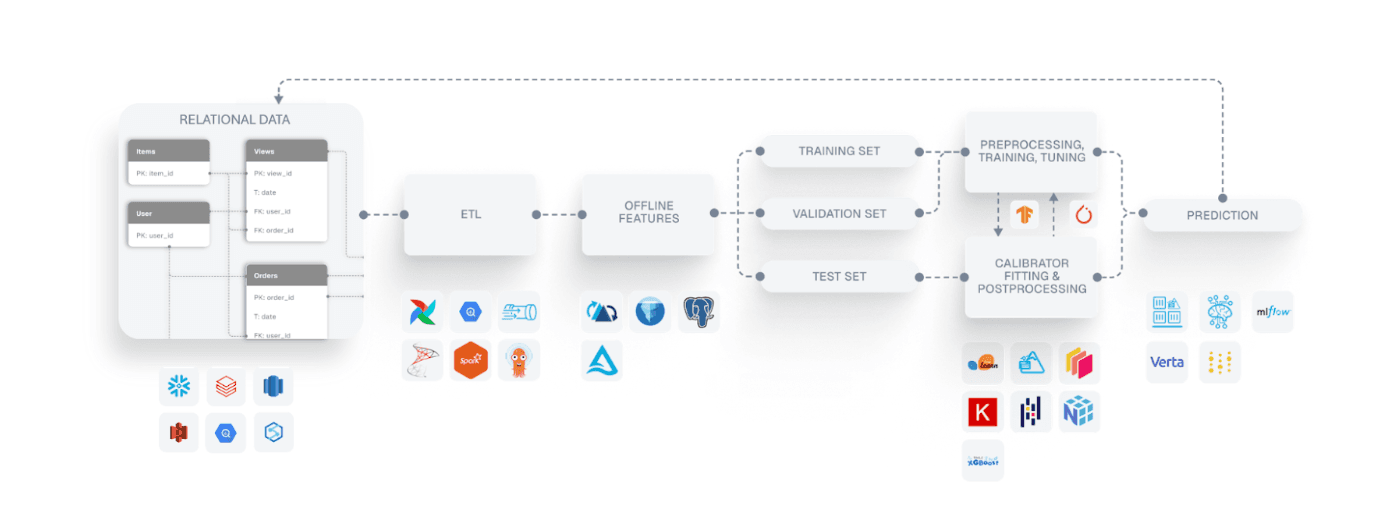
A traditional ML workflow requires flattening the data into a single training table, doing manual feature engineering, and then fitting a boosted tree or neural network model.
This framing works for many cases, and much fraud can indeed be caught with heuristics and tree-based models. However, it falls short on the most complex, high-impact cases. These often involve coordinated networks of accounts, devices, and merchants acting together in subtle, evolving patterns.
Real fraud is inherently relational and temporal. A compromised device may serve multiple accounts over a period of time. A mule account might share merchants, cards, or IPs with others. These cross-connections carry most of the signal. Yet this information disappears when data is flattened into tabular form.
A typical dataset in the financial sector could consist of billions of rows scattered across many tables, connected together with primary/foreign key relationships.
To recover some of that structure, data scientists spend weeks engineering hundreds of features to approximate network effects:
- Connectivity metrics: number of devices, IPs, or merchants linked to an account.
- Behavioral aggregates: rolling sums, ratios, and transaction velocities.
- Derived graph signals: counts of risky neighbors, clustering coefficients, local densities.
- Temporal joins: time-ordered aggregates across entity tables, carefully filtered to avoid leakage.
Graph-based learning replaces this manual process by representing data in its natural relational form. Entities such as users, accounts, or merchants become nodes, and their interactions (transactions, shared devices, or IPs) form edges. The model learns from both node attributes and the structure of connections between them, capturing complex, coordinated behaviors that handcrafted features often miss.
How It Works: Inside the Graph Transformer
At its core, a Graph Transformer learns directly from relational structure, how entities connect and interact across a dataset. It generalizes the positional encoding and multi-head attention mechanisms of text transformers, applying them not to sequences of words but to networks of entities and relationships.
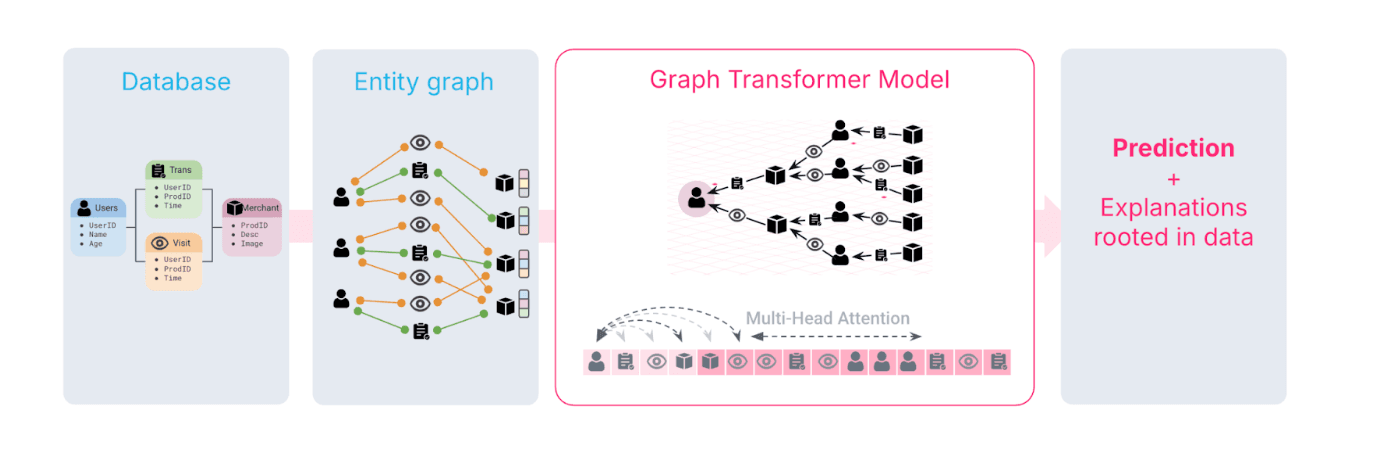
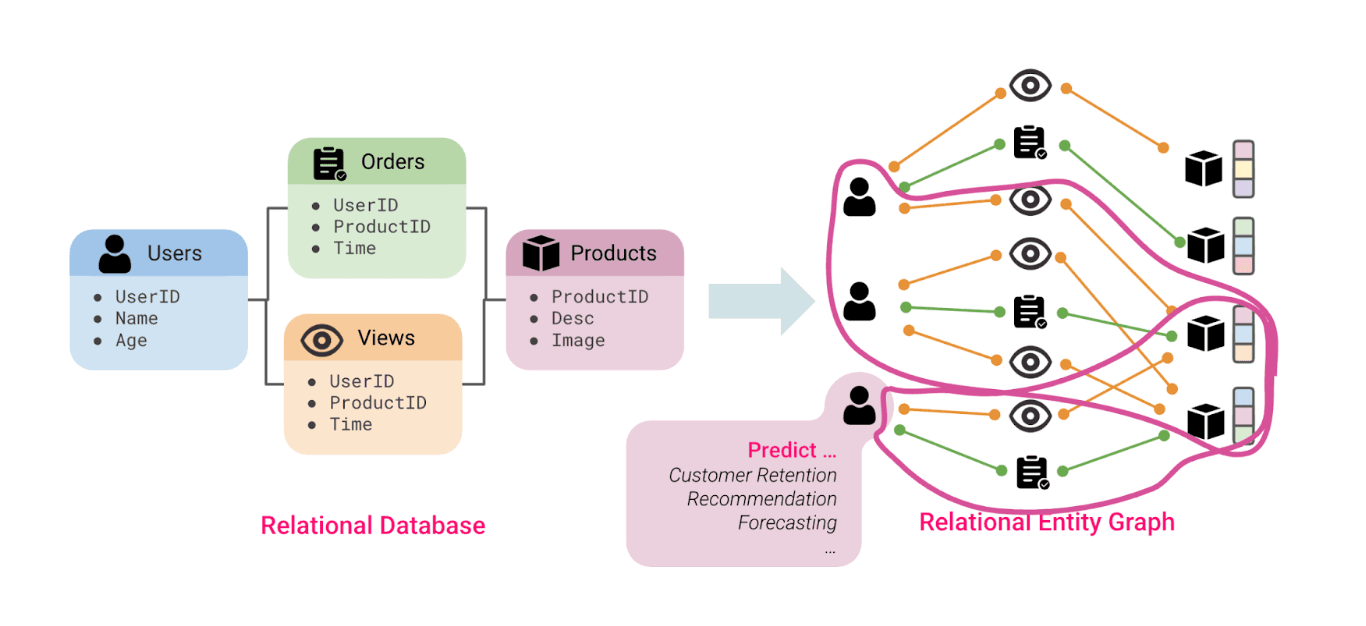
1. From Relational Tables to a Graph
Most financial datasets are relational: accounts, devices, transactions, merchants. Each table row becomes a node, and each foreign key / primary key pair becomes an edge connecting nodes across tables. Together, these form a large, heterogeneous graph describing how entities relate: which devices belong to which accounts, which merchants those accounts transact with, and so on.
When a prediction is made (for example, whether an account is involved in fraud), the model doesn’t just look at the account’s own attributes. It also follows its edges to other nodes (the connected devices, counterparties, or merchants) building a local subgraph that provides relational context.
2. Learning from Structure: Attention over Neighborhoods
Once the dataset is represented as a graph, the Graph Transformer performs message passing and attention across connected nodes. Unlike GNNs, which aggregate information uniformly from each neighbor, attention allows the model to focus on the most relevant connections:
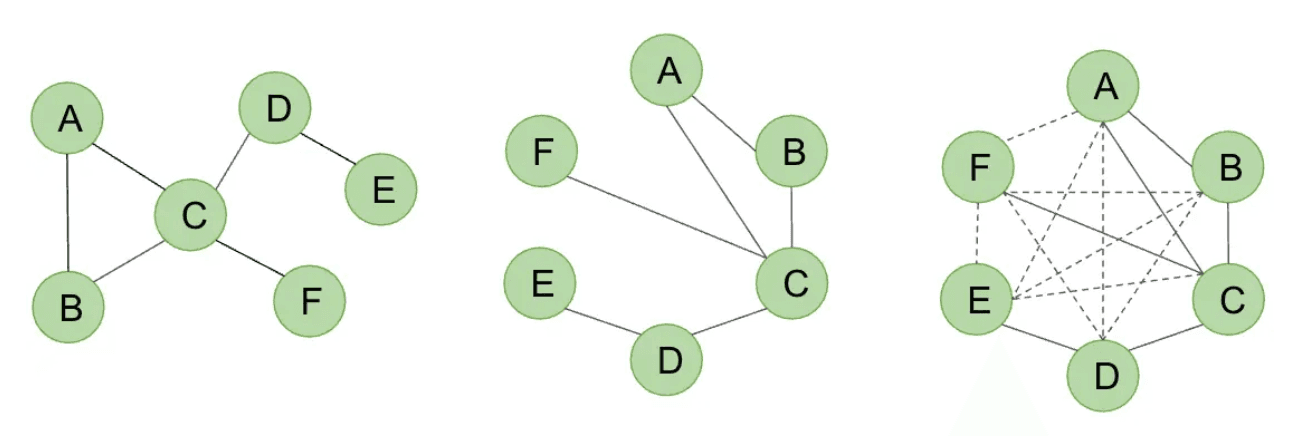
Left: Original graph structure. Center: Local attention -> nodes attend to neighbors. Right: Global attention -> nodes attend to distant nodes via added edges, capturing long-range dependencies.
Each node i computes attention weights ij that determine how much influence each neighbor j has on its updated representation. This lets the model capture long-range dependencies. For instance, an account that looks normal on its own but connects through multiple hops to known fraudulent entities.
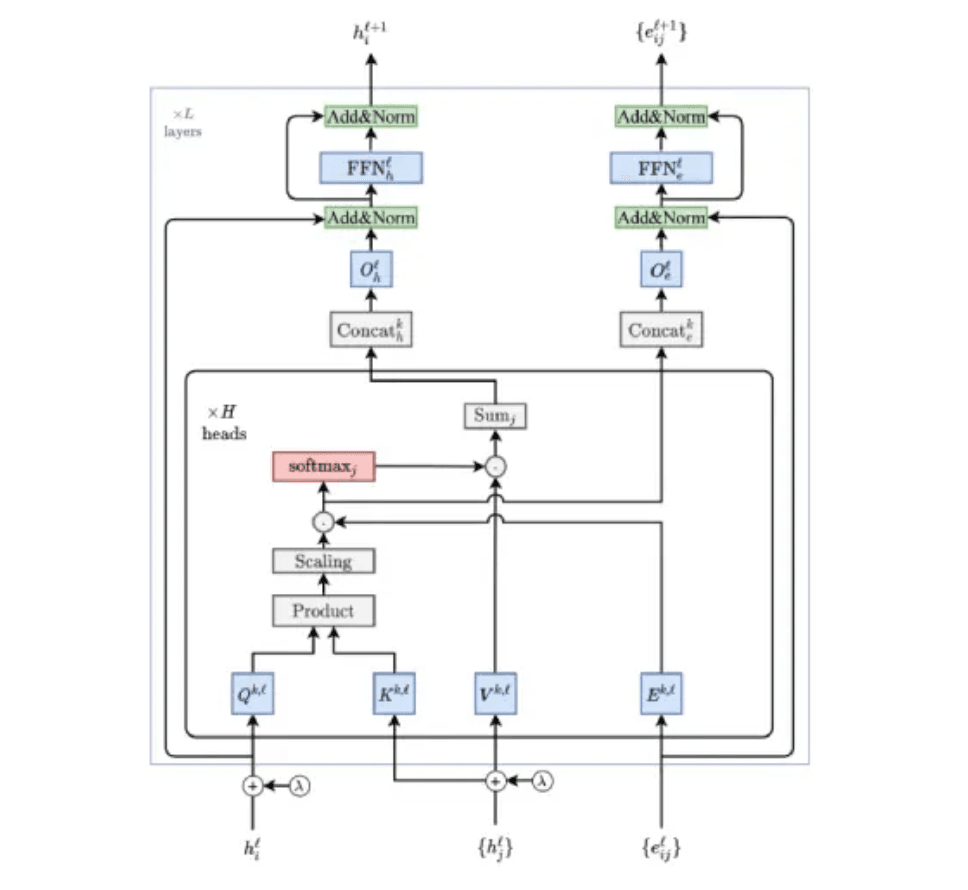
Block diagram of Graph Transformer that incorporates edge features. Source: A Generalization of Transformer Networks to Graphs
3. Integrating Context: Local Detail + Global Awareness
This architecture combines local specificity (learning the fine-grained attributes of a node) with global awareness (learning from distant but relevant parts of the graph). In practice, that means the model can detect both:
- micro-patterns, such as rapid sequences of transactions through a single device, and
- macro-structures, such as distributed laundering networks spanning many accounts.
Where tree-based models rely on engineered features to summarize these relationships, the Graph Transformer operates directly on the underlying graph structure, automatically picking up new patterns as they emerge.
4. Why It Works Better
This combination of learned attention and graph context allows the model to encode system-wide behavior in a way that’s both flexible and scalable. Many of Kumo’s customers have found that attention-based graph models outperform traditional architectures on real-world datasets:
| Use Case | Customer Existing | Production Model | Lift from GNN or Graph Transformer |
|---|---|---|---|
| On-Chain and Transfer Reversal Fraud | Large U.S. Crypto Exchange | XGBoost | +20 % AUPRC |
| Money Muling | UK Bank | Boosted Tree | +47 % £-weighted recall |
| Real-Time Mule Detection | Brazilian Neobank | LightGBM + hand-built features | +25 % weighted PRAUC |
| CNP Fraud | USA Mobile Banking App | LightGBM with hand-built features | +27 % $-weighted recall at fixed flag rate |
To learn more, feel free to check out this blog post: An Introduction to Graph Transformers
A Declarative Way to Work
Building machine learning models from scratch normally to take thousands of lines of code: managing joins, temporal windows, leakage control, negative sampling, and MLOps. The Kumo SDK replaces that boilerplate with a few simple, declarative steps.
Here’s an example drawn from a real fraud workflow: predicting card not present fraud using a transaction graph of five connected tables.
1import kumoai as kumo
2
3kumo.init(...)
4connector = kumo.SnowflakeConnector(...)
5
6credit_cards = kumo.Table.from_source_table(
7 source_table=connector.table('credit_cards'),
8 primary_key='credit_card_id',
9).infer_metadata()
10
11transactions = kumo.Table.from_source_table(
12 source_table=connector.table('transactions'),
13 time_column='timestamp',
14 primary_key='transaction_id',
15).infer_metadata()
16
17fraud_reports = kumo.Table.from_source_table(
18 source_table=connector.table('fraud_reports'),
19 time_column='timestamp',
20).infer_metadata()
21
22accounts = kumo.Table.from_source_table(
23 source_table=connector.table('accounts'),
24 primary_key='account_id',
25).infer_metadata()
26
27merchants = kumo.Table.from_source_table(
28 source_table=connector.table('merchants'),
29 primary_key='merchant_id',
30).infer_metadata()
31
32graph = kumo.Graph(
33 tables={
34 'credit_cards': credit_cards,
35 'transactions': transactions,
36 'fraud_reports': fraud_reports,
37 'accounts': accounts,
38 'merchants': merchants,
39 },
40 edges=[
41 dict(src_table='transactions', fkey='credit_card_id', dst_table='credit_cards'),
42 dict(src_table='transactions', fkey='merchant_id', dst_table='merchants'),
43 dict(src_table='fraud_reports', fkey='transaction_id', dst_table='transactions'),
44 dict(src_table='credit_cards', fkey='account_id', dst_table='accounts'),
45 ],
46)
47
48pquery = kumo.PredictiveQuery(
49 graph=graph,
50 query="PREDICT transactions.LABEL FOR EACH transactions.transaction_id"
51)
52
53trainer = kumo.Trainer(pquery.suggest_model_plan())
54training_job = trainer.fit(
55 graph=graph,
56 train_table=pquery.generate_training_table(non_blocking=True),
57 non_blocking=False,
58)The full pipeline is 60 lines of code: data connection, feature generation, model selection, training. The same task in CatBoost or even PyTorch would require thousands: joining/aggregating data into a single flat training table (dropping information in the process), and then engineering complex features in order to capture the signal that was lost.
The graph transformer automatically learns features that would otherwise be hand-crafted:
- Account–card and account–merchant relationships discovered through multi-hop connections.
- Behavioral similarities among users or merchants with overlapping transaction networks.
- Temporal spending patterns that evolve over hours or days without manual windowing or rolling aggregates.
The result is not just fewer lines of code, but a clearer way to express what the model should learn.
To learn more, you can check out the documentation for the Kumo platform as well as Kumo’s python SDK.
Control Where It Matters: Advanced Options for Power Users
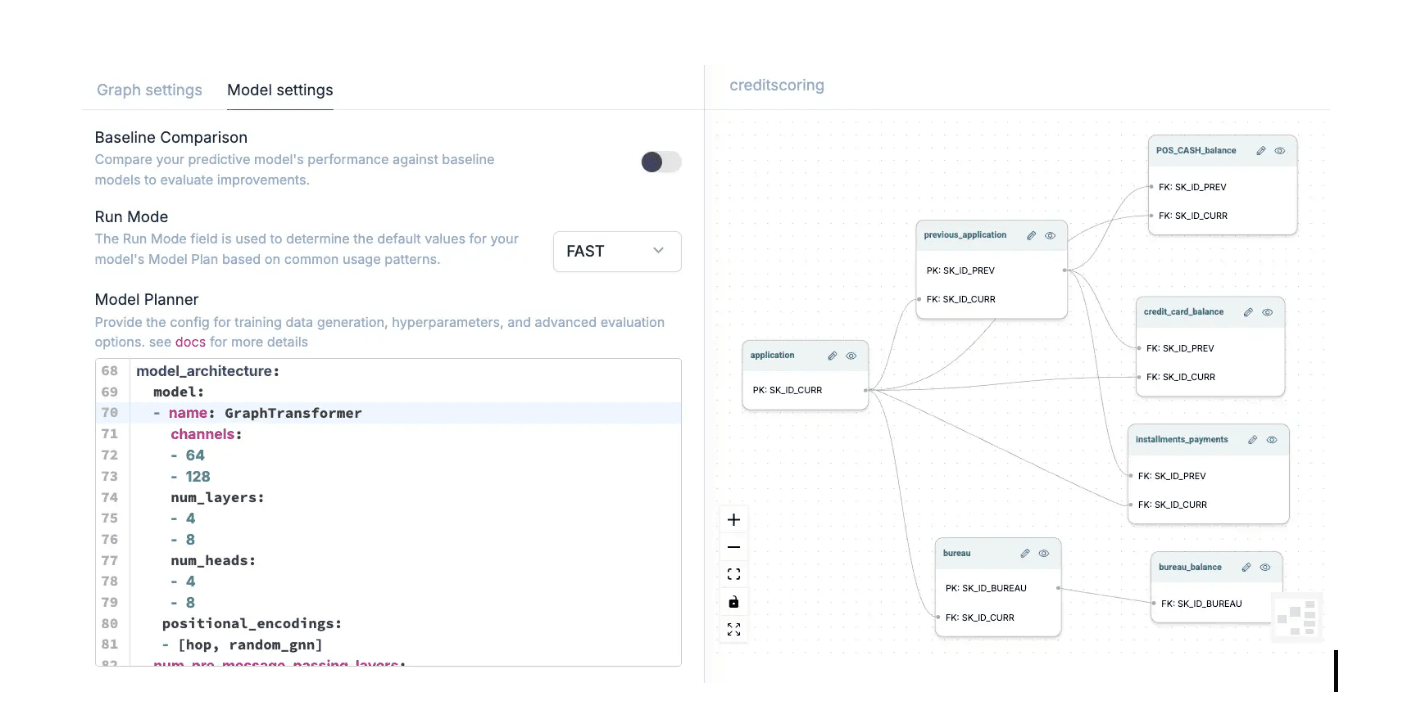
While Kumo handles much of the engineering overhead, it’s not a black box. The best results still depend on domain expertise, particularly in how the relational graph is constructed and how the model explores it.
Data scientists and subject-matter experts define the network of learning: which entities are included, which relationships connect them, and how far information should travel. This design shapes what the model can see and what it can infer.
Kumo’s Model Planner exposes the same level of configurability found in open-source frameworks like PyTorch Geometric, which Kumo’s researchers helped author. Every layer, aggregation, and sampling step can be adjusted with defaults that align to proven research practices.
For example, controlling neighborhood sampling through the num_neighbors parameter defines how many connected nodes each entity attends to during training. Increasing it broadens context, allowing the model to capture long-range dependencies; constraining it enforces locality and reduces noise.
1model_plan = pquery.suggest_model_plan()
2
3model_plan.override(
4 neighbor_sampling=dict(
5 num_neighbors=[
6 {"hop": 1, "default": 10},
7 {"hop": 2, "default": 5},
8 {"hop": 3, "default": 2},
9 ]
10 ),
11 model_architecture=dict(
12 graph_transformer=dict(
13 channels=[256],
14 num_heads=[8],
15 num_layers=[3],
16 )
17 ),
18)
19Neighborhood size, message-passing depth, and attention heads together control the effective “field of view” for each node, a powerful lever for domain experts who know which connections carry real signal.
Other options include:
- Edge-type weighting, giving certain connections (e.g., account–card vs. account–merchant) more influence.
- Custom aggregation functions, such as mean, sum, or attention-based pooling, to tailor how transaction context is combined.
- Feature selection and masking, useful when some attributes (e.g., marketing or demographic fields) introduce noise.
- Embedding sharing and reuse, allowing one trained graph (say, a device network) to initialize another model, such as a merchant risk detector.
This interface is what makes declarative relational modeling practical. It removes repetitive work while elevating the impact of domain experts.
Real-World Applications of Graph Transformers in Fraud Detection
Financial institutions are beginning to adopt Graph Transformers in production with Kumo, integrating them into existing fraud detection systems to improve performance while reducing feature-engineering overhead.
Large U.S. Crypto Exchange - On-Chain and Transfer Reversal Fraud: The Large U.S. Crypto Exchange established XGBoost models, built on hundreds of engineered features, and struggled to track new on-chain behaviors. A Graph Transformer trained on relational blockchain data doubled AUPRC for address-level fraud and improved average precision by 10–20 % on transfer-reversal detection. Weekly retraining captures evolving network structures and regulatory shifts without manual feature updates.
UK Bank - Money Muling: The institution’s prior model (XGBoost with handcrafted graph features) achieved strong baseline results but plateaued. Replacing these features with supervised graph embeddings improved £-weighted recall by 47 % at the same precision. The embeddings were integrated directly into the existing serving stack, requiring no infrastructure changes.
Brazilian Neobank - Real-Time Mule Detection: Legacy LightGBM models relied on extensive feature pipelines across regions. By consolidating data into a unified relational graph, the Graph Transformer achieved a 25 % lift in weighted PRAUC, supporting sub-100 ms latency at thousands of QPS.
US Mobile Banking App - Card-Not-Present (CNP) Fraud: A LightGBM model with 30 manually designed features struggled to capture network context. Adding graph embeddings within Snowflake SPCS improved $-weighted recall by 27 % at a fixed flag rate, without modifying serving infrastructure.
Across deployments, Graph Transformers trained through Kumo’s declarative graph framework have shown 20–100 % improvements in key metrics and an order-of-magnitude reduction in feature-engineering complexity, while integrating cleanly with existing production workflows.
Explainability in the Graph Era
Explainability is essential for fraud detection systems. Model risk teams need transparency for validation, data scientists use it to identify potential leakage or bias, and investigators rely on clear reasoning to act on alerts.
Tree-based models provide feature importances or SHAP values, which help quantify which columns drive predictions. However, these explanations are limited to individual features and can’t describe relational risk: for example, how an account connects to others through shared devices or merchants.
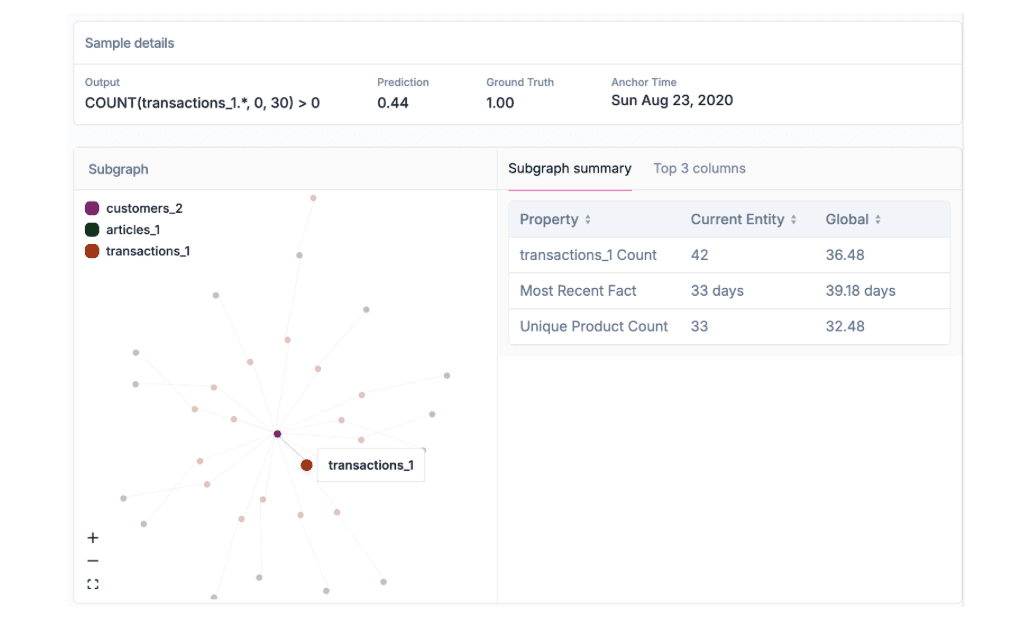
Graph models make these relationships explicit. Each prediction can be traced through the network: e.g., “Account A is two hops from a confirmed mule via shared IP and merchant.” Embeddings allow similarity search to locate past, confirmed cases with matching patterns. Partial-dependence plots help quantify how risk changes with the density or proximity of connected fraud.
Explanations can be exported in structured formats for downstream tools, whether for dashboards, audit workflows, or natural-language summaries generated by LLMs.
This approach provides interpretable, network-level insight into model behavior while maintaining the rigor needed for compliance and operational review.
Managed Infrastructure for Scale
Training Graph Transformers at enterprise scale means handling billions of nodes, many edge types, and time-stamped relationships, a challenge that goes far beyond GPU capacity.
Kumo’s managed backend abstracts all that complexity. Its architecture combines:
- Data Engine – Connects directly to sources like Snowflake, Databricks, or S3, reading raw relational data without replication.
- AI Engine – Builds the graph in memory, performs online neighborhood sampling, and orchestrates distributed GPU training with temporal correctness.
- Control Plane – Handles authentication, metadata, and orchestration through a secure private network.
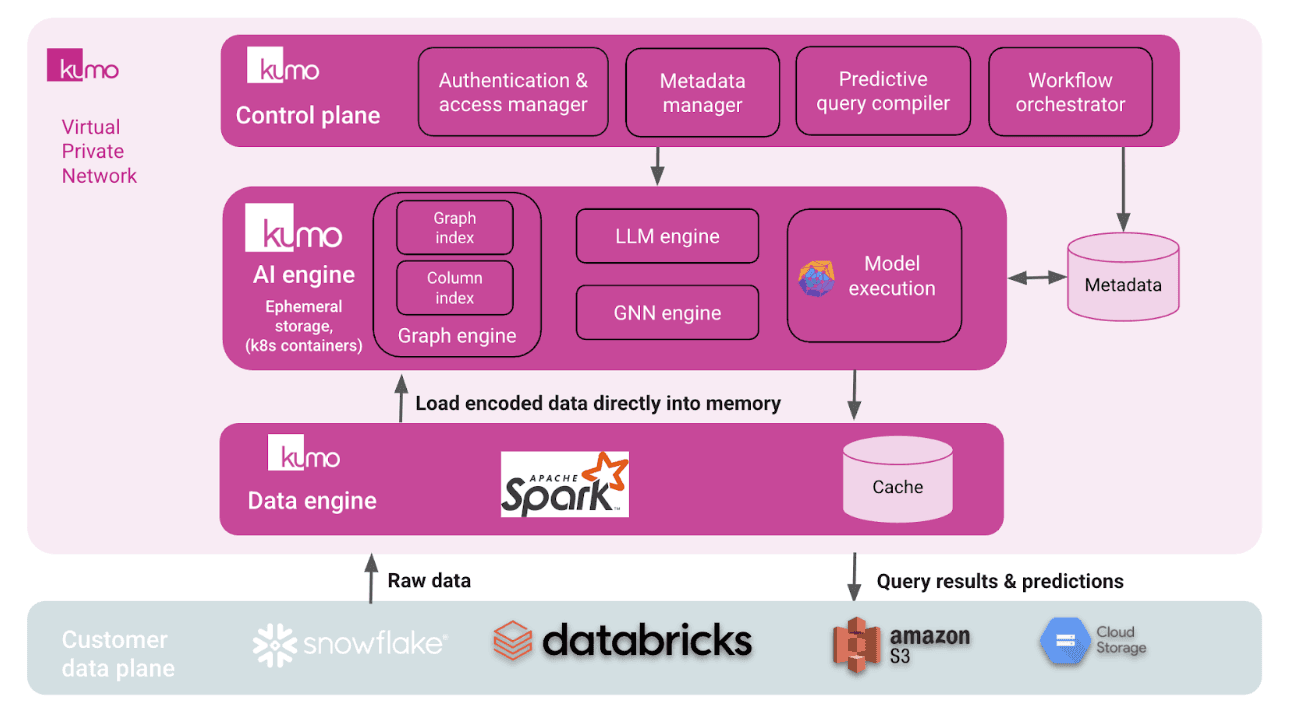
This design enables efficient, large-scale graph learning (up to tens of billions of nodes) without custom infrastructure. Kumo can run as a managed SaaS or within a customer’s VPC, ensuring data stays within enterprise boundaries.
In practice, this lets data science teams focus on modeling rather than pipelines, achieving production-grade scalability and performance at a fraction of the operational cost.
Beyond Fraud: Growth, Credit & Consumer Use-Cases
The same relational modeling framework used for fraud detection can be used by other business units, such as credit risk, customer retention, and personalization.
Graph learning doesn’t just enhance accuracy, it democratizes modeling velocity. Because the graph structure and training orchestration are automated, teams can move from connected data to a trained model in days, even without deep machine learning experience.
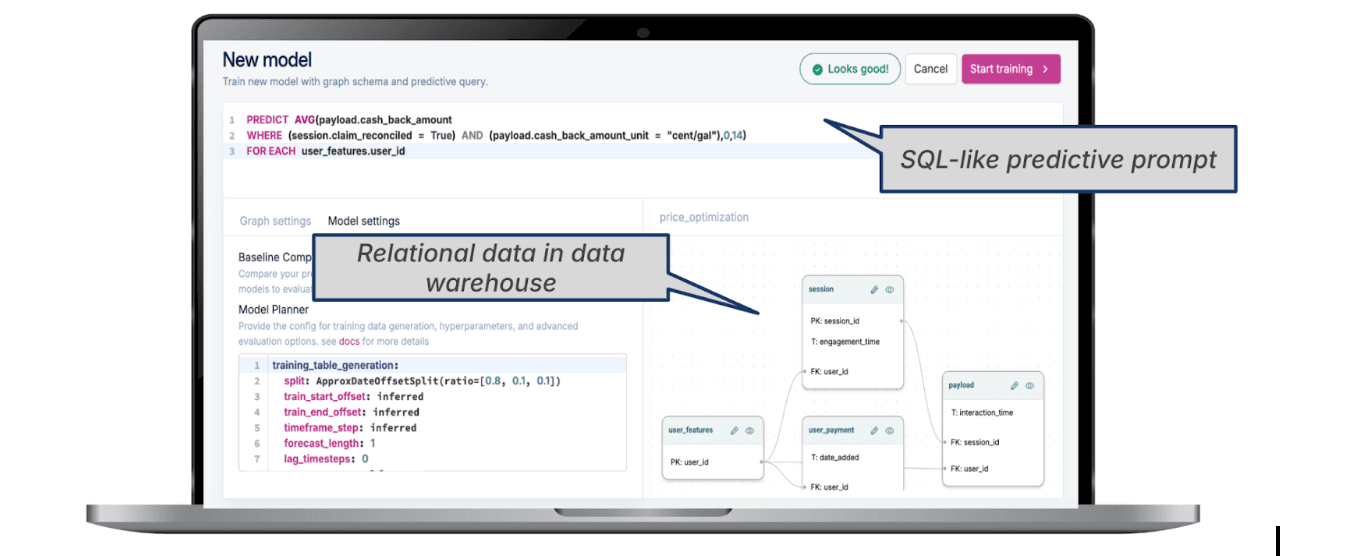
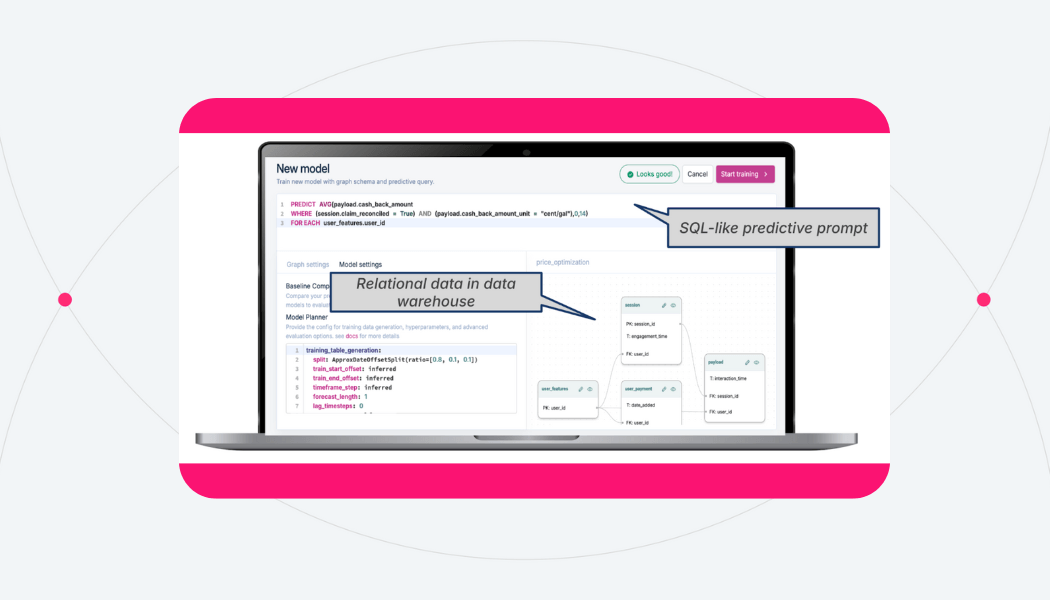
Kumo’s predictive query language makes it easy for domain experts to quickly build models, using a language similar to SQL.
Here are some examples of how other teams have used Kumo to solve complex relational modeling problems beyond fraud:
- Brazilian Payments Platform - Merchant Churn: The main challenge was distinguishing temporary inactivity (for example, during holidays) from actual churn. By learning both the relationships between merchants and customers and the timing of transactions, the graph model identified 82 % of true churners and reduced unnecessary outreach.
- US Neobank - Next Best Action: A growth team without a mature ML setup needed a faster way to test personalized offers. Using graph-based modeling, they built a recommendation model in four days that improved accuracy by 76 % over their heuristic baseline and accelerated in-app experimentation.
Looking Ahead
Traditional fraud models rely on manually engineered features to capture new behaviors. As fraud tactics evolve, this creates a cycle of constant updates: rebuilding features, retraining models, and redeploying pipelines.
Transformer-based graph models take a different approach. Because they learn directly from relationships in the data, they can pick up new transaction patterns or account linkages as they appear. Instead of rewriting features every few months, teams can retrain the model and have it adjust automatically to new behaviors.
In short, machine learning is beginning to model the world (and fraud within it) as it truly is: connected.
Join our community on Discord.
Connect with developers and data professionals, share ideas, get support, and stay informed about product updates, events, and best practices.